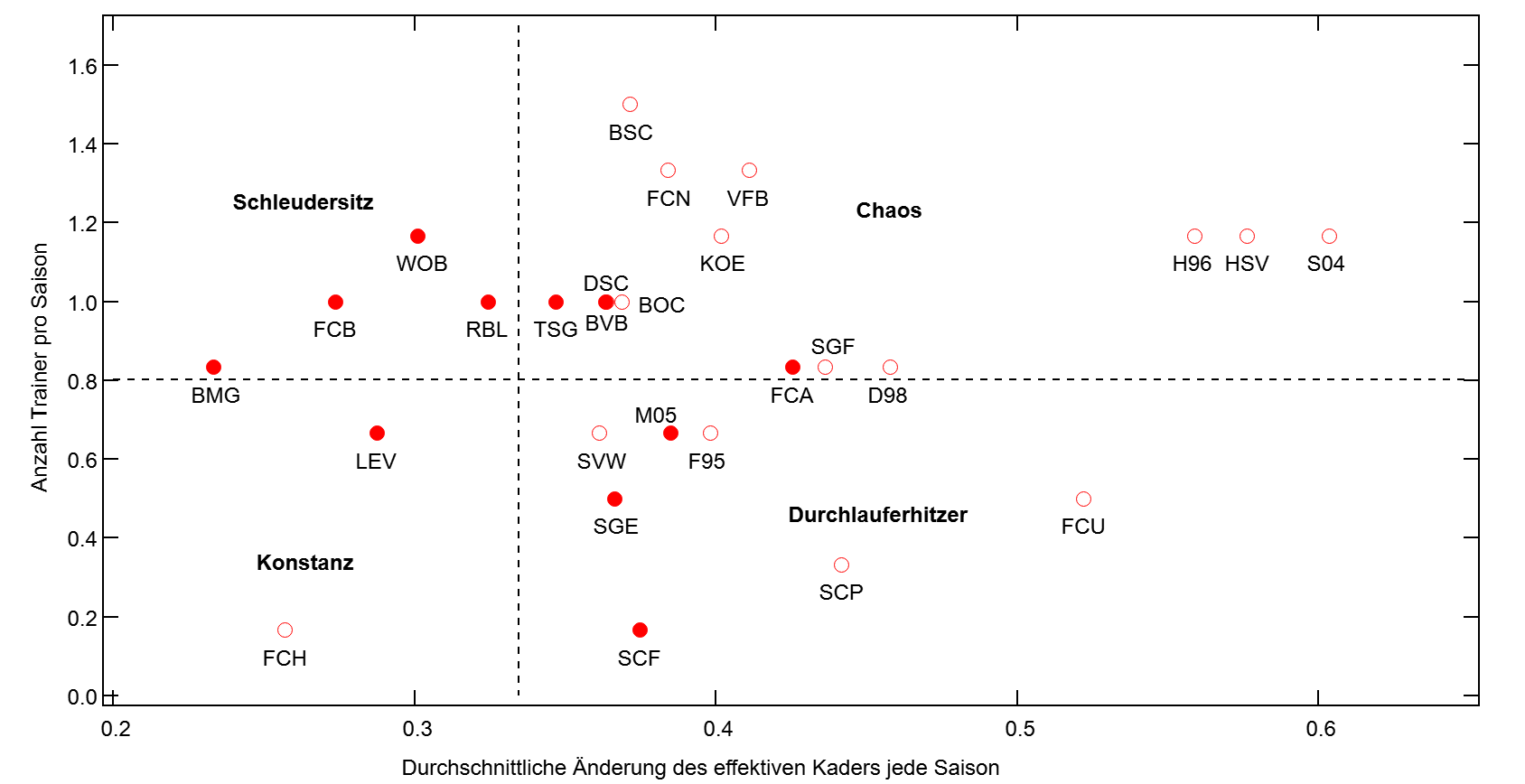
Basierend auf dem oben beschriebenen Modell für Änderungen des „effektiven Kaders“, hier eine kleine Spielerei:
Habe hier mal alle (ex-)BuLi-Vereine seit der Saison 2017/18 dargestellt wie viel sie im Schnitt ihren Kader verändern und wie viele Trainer sie in der Zeit hatten.
Mit Vollkreisen dargestellt sind dabei die Vereine, die durchgängig in der ersten Liga waren, und mit Ringen diejenigen mit Auf- und Abstiegen seit 2017/18 – und deswegen schon größere Kaderumbrüche dabei hatten. Die gestrichelten Linien sind dabei die Mittelwerte aller 11 Vereine, die durchgängig in der ersten Liga waren.
ERRATUM
Hatte in einer früheren Version die Anzahl der Trainer falsch berechnet. Die (hoffentlich) korrekte Version wurde neu hochgeladen. Bielefeld und Dortmund liegen dadurch jetzt nahezu identisch aufeinander.
Wo ich diesen Post eh schon editieren musste noch die obligatorischen Beobachtungen:
von den sieben Clubs die ihren Kader am wenigsten verändern (mussten) gehören mit Bayern plus den vier „50+1“-Ausnahmen/Umgehungen (LEV, WOB, RaBa, TSG), 5 Clubs bei denen Geld nur bedingt eine Rolle spielt (mutmaßlich)
bis auf Leverkusen sind es auch diese Clubs unter den permanenten Bundesligisten, deren Trainerstuhl am lockersten ist, zusammen mit Dortmund
Dortmund hat von den „reichen“ Klubs den größten Kaderumbau (Stichwort: Geschäftsmodell und Busanschlag)
die „kleineren“ Clubs haben idR viel größere Kaderveränderungen (Stichworte: Auf- /Abstiege und „weggekauft“)
Eintracht und Bremen sind von den „großen Traditionsvereinen“ mit am konservativsten
Hannover, HSV und Schalke erreichen ihr eigenes Level an „Chaos“
Zusammenfassend würde ich es in etwa so gruppieren:
oben links sind die großen/reichen Clubs
unten rechts die „genügsamen“ kleinen Clubs, die gute Arbeit leisten
oben rechts sind die großen Clubs im Panic-Mode
unten links ist Heidenheim
Vereine die aus diesem Schema ausreißen wären also besonders interessant anzuschauen. Weiß jemand warum Gladbach so konservativ in Sachen Transfers war? Und Leverkusen schien zufrieden damit zu sein ständig die CL zu verpassen?
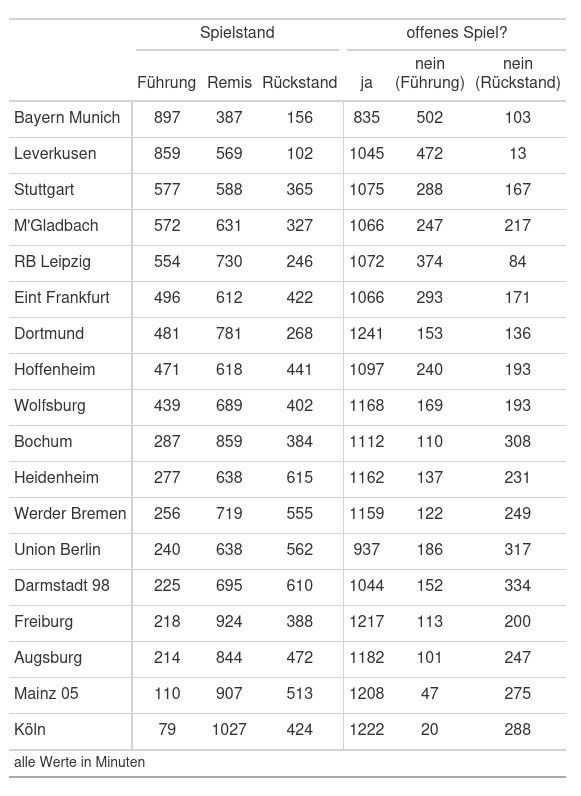
In der aktuellen Folge war es kurz Thema beim Mainz-Wolfsburg Spiel wie selten bisher die Mainzer in Führung lagen. Kurz vor der Winterpause hatte ich mich indirekt damit beschäftigt gehabt, dementsprechend war es recht leicht für mich eine Tabelle dazu zu erzeugen.
Im Gegensatz zu der Vermutung von @passwinkel, der Effzeh lag tatsächlich noch seltener in Führung in dieser Saison als die 05er.
Kurze Erklärung, was ich als offenes Spiel bezeichnet habe. Das sind alle Spielstände innerhalb der ersten 70 Minuten, wenn der Torvorsprung nicht mehr als ein Tor beträgt. Die 70 ist natürlich ein bisschen zufällig gewählt. Meine Überlegung war es, für die meisten Mannschaften stehen die Chancen noch ganz gut mit 20 oder mehr Minuten einen Rückstand mit einem Tor in einen Sieg umzuwandeln.
Außerdem fehlen die Nachspielzeiten bei den Minuten, weil ich dazu keinen Daten habe.
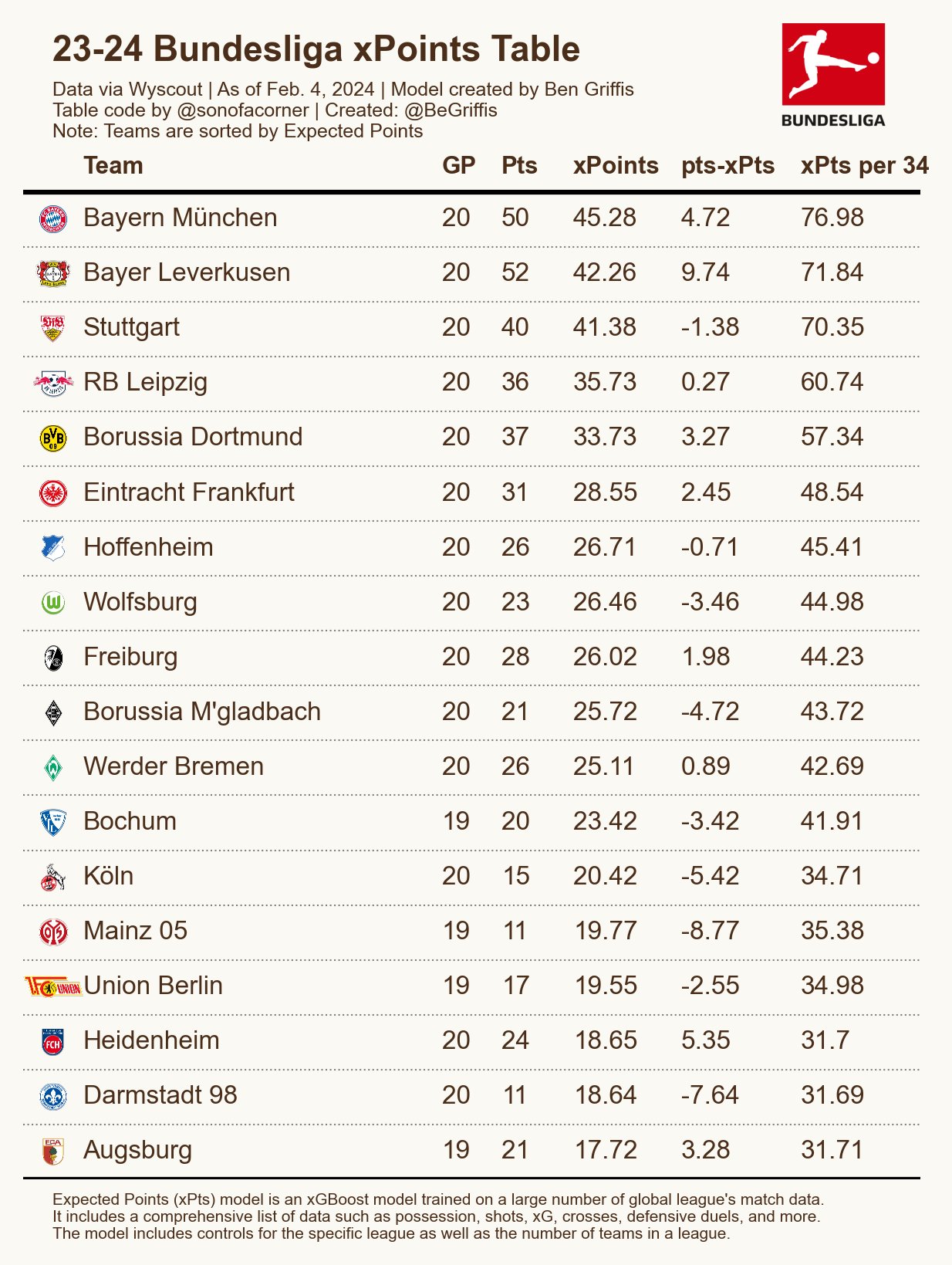
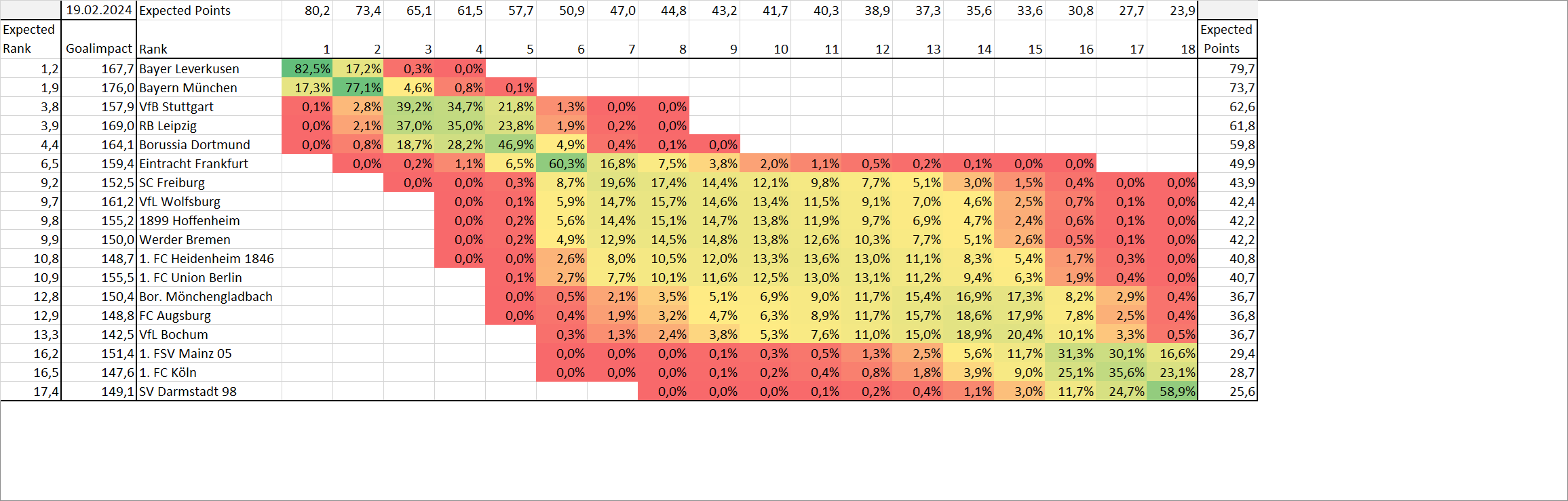
Ich bin auf Twitter über eine xPts Tabelle von Ben Griffis gestolpert (den vielleicht einige aufgrund seiner Wyscout Spieler Grafiken kennen). Er hat dafür ein Modell erstellt bei dem er noch andere Statistiken als nur die xG einfließen lässt, was im Vergleich zu den anderen xPts Tabellen doch eher unüblich ist. Dementsprechend sind auch einige der Werte etwas unterschiedlich.
Hier noch der Verweis auf den Tweet, damit man es sich direkt bei ihm ansehen kann. Er hat das auch für die anderen Top 5 Ligen gemacht.
Die Werte unterscheiden sich bei einigen Teams dann doch etwas deutlicher zum klassischen Ansatz bei xPts. Ich nehme als Vergleich einfach mal die xPts Werte von mir, die ich hier vor Monaten vorgestellt habe.
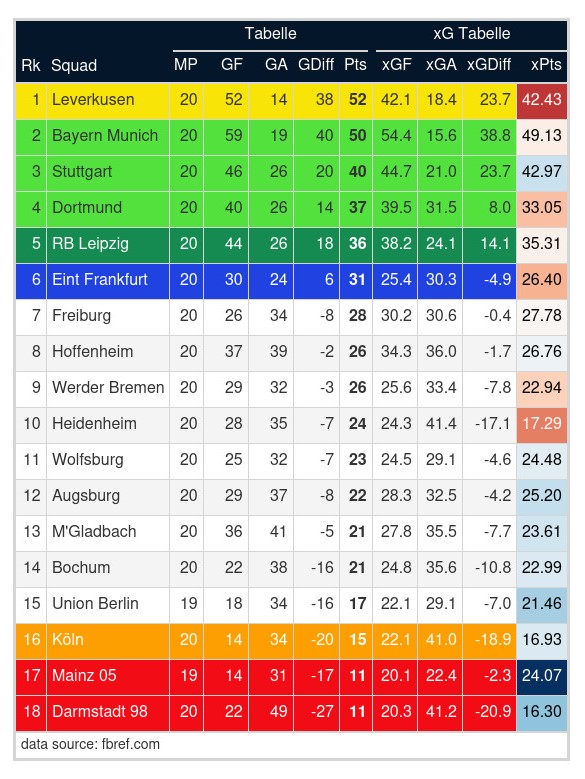
Wenn ich direkt mal auf die beiden größten Unter- und Overperformer eingehe (Leverkusen & Mainz 05), ändert sich der Wert bei Leverkusen fast gar nicht während der xPts-Wert von Mainz 05 bei seinem Modell um 4.3 geringer ist. Es bleibt aber dabei nach xPts ist Mainz 05 der größte Unterperfomer. Die größte Überraschung ist für mich wie unterschiedlich der FC Augsburg bewertet wird. Es fehlt bei ihm zwar noch das Spiel Bochum-Augsburg. Aber auch wenn man den Wert vom 19.Spieltag nimmt ist der Unterschied von 22.94 zu 17.72 doch recht deutlich. Persönlich muss ich sagen fühlt sich die Einordnung vom FCA als eines der Durchschnittsteams hinter den Top 5 richtiger im Vergleich zur Einordnung als zweitschwächstes Team. Da wäre es interessant zu wissen, warum das Modell die Augsburger so einordnet. Im Gegensatz dazu schneidet der Effzeh doch deutlich besser ab (16.93 zu 20.42), gehört aber weiterhin zu der Gruppe der unteren Teams. Die sonstigen Differenzen sind abgesehen von den Bayern (3.85 xPts) nicht größer als 2.5.
Sau interessant, aber irgendwie wertlos solange er die Methodik dahinter nicht erklärt hoffe die wird irgendwann nachgereicht. (Oder steht es da irgendwo aber shitter zeigt es nicht an, weil ich keinen Account habe?)
Im Grunde ist Pts-xPts ja ein Gradmesser für „Glück + Qualität der Torschützen“, oder? Krass wie weit Leverkusen da abweicht. Liegt das einfach daran, dass Grimaldo ständig das selbe Tor copy-pasted obwohl es einen niedrigen xG hat?
Der größte Zufallsfaktor, der von xPts nicht abgebildet wird, dürfte der Spielverlauf sein.
Wenn ein spielstarkes Team wie Bayern nach drei Minuten in Führung oder Rückstand geht, ändert es an der Spieldynamik wenig. Sie werden weiter das Spiel machen und der Gegner auf Konter lauern.
Wenn ein spielschwaches Team wie Darmstadt nach drei Minuten in Führung oder Rückstand geht, ändert es an der Spieldynamik ebenso wenig. Sie werden weiter hinten drin stehen und den Gegner das Spiel machen lassen.
Zwischen Bayern und Darmstadt hast du aber lauter pragmatisch agierende Teams, die sich situativ je nach Spielverlauf eher hinten rein stellen oder selber das Spiel machen. Bei diesen Teams kippt die ganze Spieldynamik mit jedem Tor. Wenn Bremen nach zwei Minuten gegen Mainz führt und Mainz am Ende mit den höheren xG aus dem Spiel geht, heißt es ja noch lange nicht, dass Mainz die höhere Siegwahrscheinlichkeit als Bremen hatte, da sich die Spieldynamik mit einem Ausgleich wieder komplett verändert hätte.
Zusätzliche Paramter zu nutzen, könnte also insbesondere für diese Art von Spielen zwischen zwei pragmatisch agierenden Teams Vorteile haben.
Er erwähnt schon seine Methodik, nämlich dass er ein XGBoost Modell dafür verwendet hat. XGBoost ist ein Machine Learning Algorithmus, der auf Entscheidungsbäumen basiert. Dabei wird das statistische Verfahren, Gradient Boosting, verwendet. Viel mehr will ich da aber auch gar nicht drauf eingehen, da es einiges an statistischen Vorkenntnissen braucht.
Wie genau einige der Statistiken eingeflossen sind wird er auch nicht sagen können, da Machine Learning Modelle Black Box Modelle sind. Es gibt ein paar Methoden wie man im Nachhinein den Einfluss von Variablen abschätzen kann, aber 100%ige Gewissheit hat man dann trotzdem nicht.
Was mir aber tatsächlich auch fehlt ist die komplette Liste der Variablen, weil so ist es noch schwieriger das Modell einzuschätzen.
So kann man es denke ich ganz gut zusammenfassen. Teams mit hoher individuellen Qualität haben sowieso die Tendenz besser abzuschneiden als die xG, also sollte sich das auch auf die xPts übertragen.
Das ist auch gar nicht so einfach bei der Umsetzung. Es ist schwer abzuschätzen wie sich die Spieldynamik bei einem Ausgleichstreffer verändert. Oft genug ist es auch, dass sich nichts verändert, da die Mannschaft, die die Führung verteidigt hat, es nicht mehr schafft den Schalter umzulegen. Die andere Mannschaft drückt dann noch weiter auf den Sieg. Generell würde ich behaupten sieht man solche Veränderungen eher erst später im Spiel. Das Risiko ist recht hoch doch noch irgendwie mindestens ein Gegentor zu fangen, wenn sich ein Team 88 Minuten nur darauf beschränkt zu verteidigen.
Bei Siegwahrscheinlichkeit bin ich mir nicht ganz sicher was du damit meinst. Nur bezogen auf das eine Spiel oder wenn man das Spiel so x-mal simulieren würde. Auf das eine Spiel bezogen wächst natürlich die Siegwahrscheinlichkeit mit jeder Minute, die ein Team in Führung liegt. Bei den meisten xPts Ansätzen ist es, dass man sagt wenn das Spiel x-mal mit genau den Torchancen wiederholt werden würde, wären die erwarteten Wahrscheinlichkeiten für einen Sieg für eines der beiden Teams oder Unentschieden so und so.
Um auf das Modell von Ben Griffis zurückzukommen, ich tippe er hat nur Statistiken, die sich
auf das ganze Spiel beziehen, miteingebaut. Also dürfte der Spielverlauf oder die Spieldynamik noch nicht wirklich mit einfließen. Auch auf eine Frage in den Kommentaren hat er geantwortet, dass er noch überlegt so etwas wie Spielverlauf miteinzubauen.
Wenn mal vergleicht wie lange es gebraucht hat, dass Dortmund ihre 9 Punkte Vorsprung verspielt hat, dann waren es 10 Spieltage, wird also knapp und Leverkusen ist ja einfach super stabil und Bayern eher weniger, da ist eine Trendwende eher unwahrscheinlich.
Guten Morgen.
Bin mir nicht ganz sicher, ob das hier hin gehört, aber ich musste die letzten Tage drüber nachdenken und hoffe da hat jemand ein bisschen mehr Ahnung von als ich.
Habe letztens diesen Reddit Thread über das Eigenkapital der Vereine in der 1. Und 2. Buli gesehen: https://www.reddit.com/r/Bundesliga/s/3tOvDgJtgV
In der letzten Rasenfunk Folge ging es ja noch Mal darum, wie knapp die Vereine eigentlich wirtschaften. Wenn man sich jetzt diese Aufstellung ansieht, schaut das Ganze jedoch anders aus (außer natürlich bei Schalke, juhu…).
Werden da unterschiedliche Dinge miteinander vermischt, oder wie kommt die Diskrepanz zu Stande?
Das bilanzielle Eigenkapital ist nur eingeschränkt aussagenkräftig, weil es sehr davon abhängig, wie Spielerverträge bilanziert werden. Es gibt ja keine echten anfassbaren Anlagegüter. Alles sind nur immaterielle Vermögenswerte und entsprechend viel „Spielraum“ gibt es da in der Bilanzierung. Je nach Ziel ist der Wert dann hoch (Spiellizenz erhalten, Fremdkapital aufnehmen) oder niedrig (Gewinnsteuern vermeiden).
It’s complicated. Deswegen ist Bilanzlesen eine Kunst (und keine die ich beherrsche). Im Prinzip ist das Eigenkapital schon richtig. Es ist die „Risikotragfähigkeit“. Zusätzlich müsste man noch heraus lesen wie groß das Risiko denn ist. Da gibt es grundsätzlich zwei Quellen:
Finanzierungsrisiko
Geschäftsrisiko
Finanzierungsrisiko ist eine Funktion des Fremdkapitals. Man könnte als Kennzahl den „Leverage“ nehmen (Fremdkapital durch Eigenkapital).
Geschäftsrisiko sind Dinge wie schlechte Transfers und Abstieg. Das Risiko für schlechte Transfers ließe sich aus Verteilung der Spielermarktwerte ablesen. Je ungleicher, desto riskanter. Das Abstiegsrisiko aus Tabellen wie der oben grposteten.
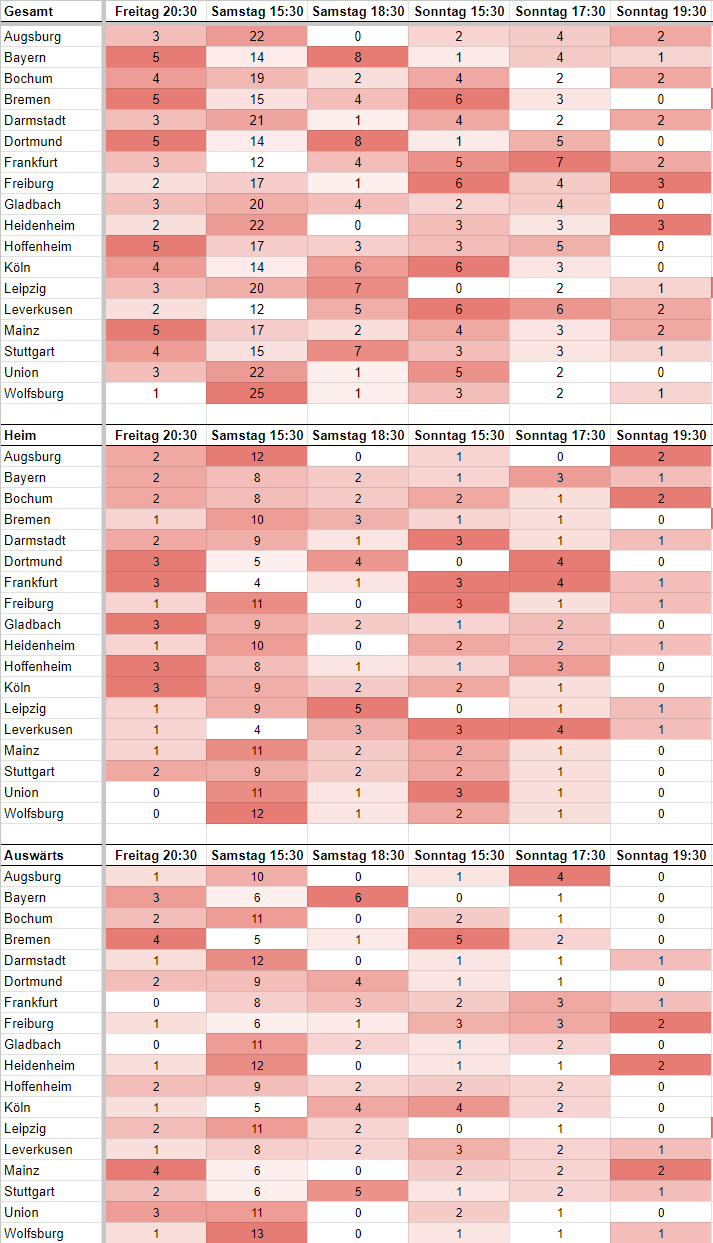
Ich bin mir nicht sicher, ob es hier am besten reinpasst, aber ich habe während der Saison eine Übersicht über die Ansetzungen gemacht und da jetzt die Spieltage 31–33 terminiert wurden, ist die Übersicht komplett. Die Englische Woche habe ich mal rausgelassen.
Update: Die Farben waren bisschen komisch. Jetzt geben sie an, wer innerhalb einer Spalte am meisten angesetzt wird. Von weiß (am wenigsten) zu dunkelrot (am meisten). Außerdem ist es jetzt einfarbig, um Menschen mit Farbsehschwäche nicht auszuschließen.
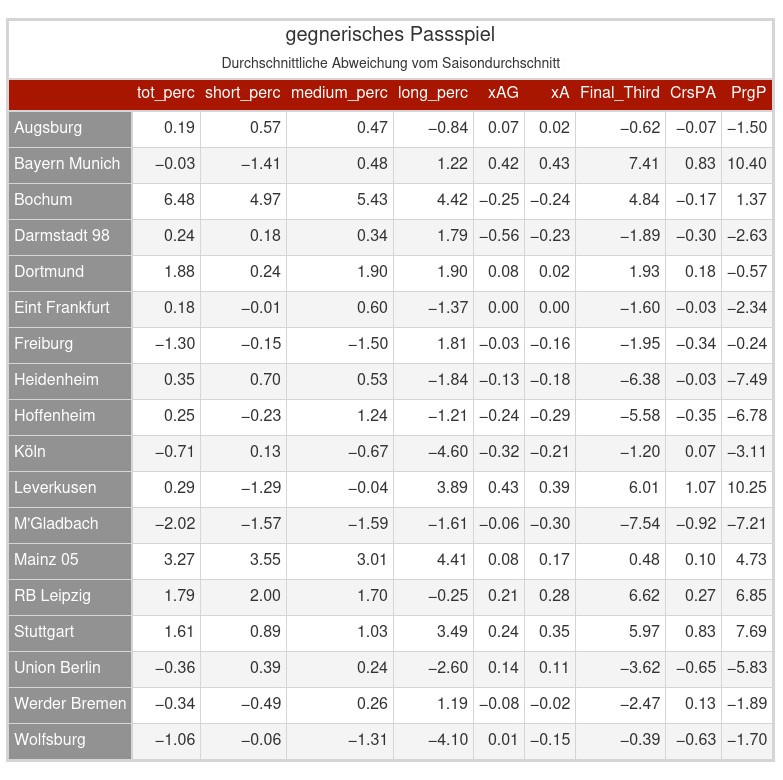
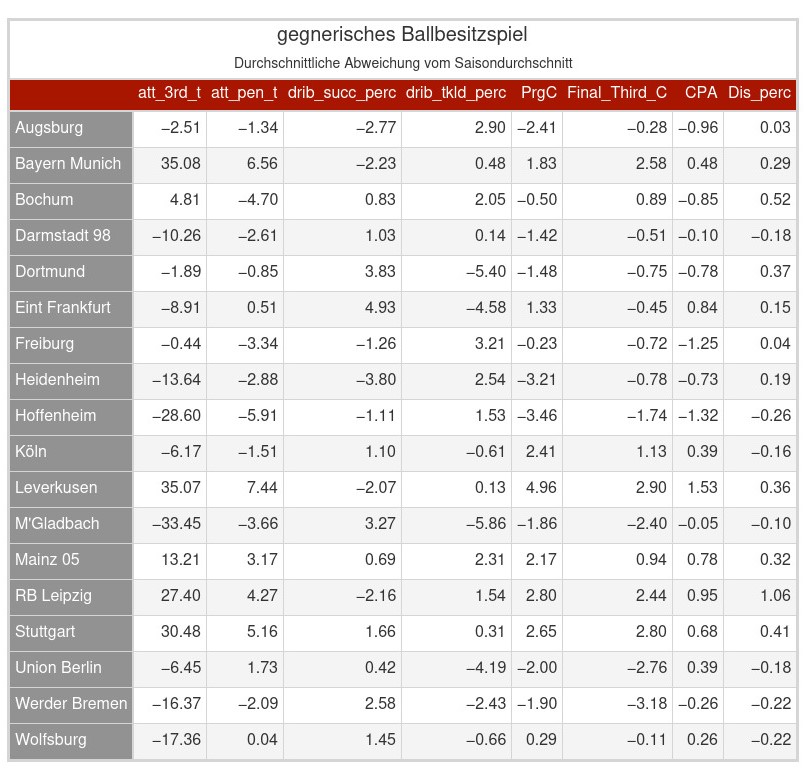
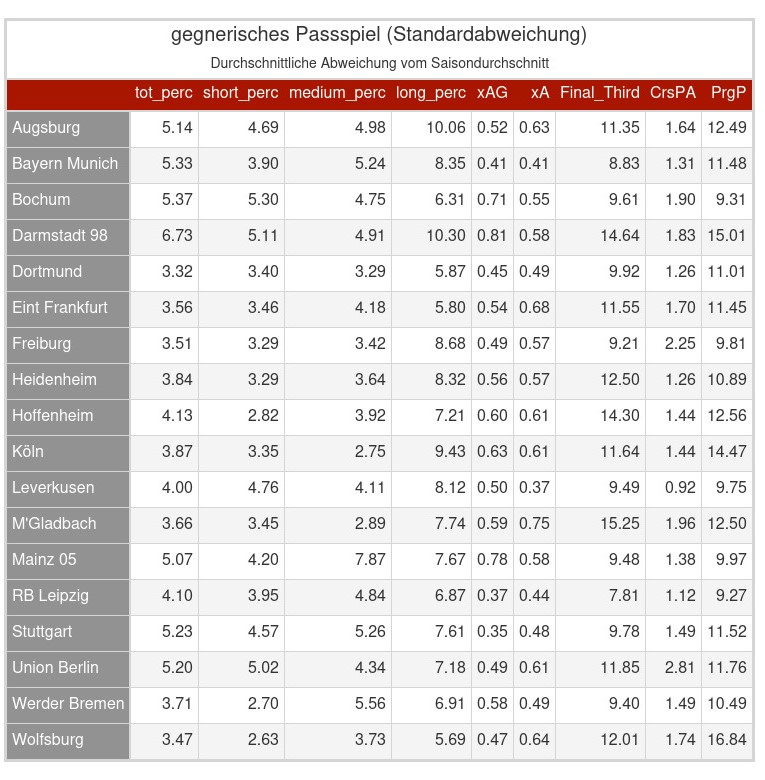
Ich habe mir die Defensiven der BL-Vereine aus einer bisschen anderen Perspektive angesehen. Statt Statistiken wie Interceptions oder gewonnene Tackle pro Spiel zu betrachten habe ich verglichen inwieweit die Teams in der Lage sind ihre Gegner von ihrem Spiel oder auch ihren Qualitäten abzubringen. Um ein Beispiel zu nennen, die 6.48 bei Bochum in der Spalte „tot_perc“ bedueten, in Spielen gegen Bochum sinkt im Durchschnitt die Passquote des Gegners um 6.48% im Vergleich zur jeweiligen durchschnittlichen Saisonpassquote. Ein Gegenbeispiel wäre Gladbach, in den Spielen hat der Gegner im Durchschnitt eine um 2.02% bessere Passquote im Vergleich zu der jeweiligen durchschnittlichen Saisonstatistik. Also sind positive Werte für die jeweilige Mannschaft eher positiv zu sehen und negative Werte eher negativ. Passquoten sind dafür nicht das ideale Beispiel, da es nicht grundsätzlich so bewertet werden kann, dass die Passqualität unbedingt zu oder abnimmt, sondern es kann auch nur auf einen veränderten Spielstil hinweisen. Gerade beim Beispiel Bochum wird es denke ich eher so sein, dass es darauf hindeutet, dass Bochum seinen Gegner das eigene Spiel aufdrängt und diese direkter spielen als sonst üblich. Bei einigen der Statistiken kann das hingegen leichter als das Unterdrücken oder Zulassen von Qualitäten ausgelegt werden. Die Namen der Variablen sind teilweise leicht verändert, aber ich denke man sollte trotzdem bei allen die Beschreibungen recht einfach auf FBref finden, wenn es unklar sein sollte.
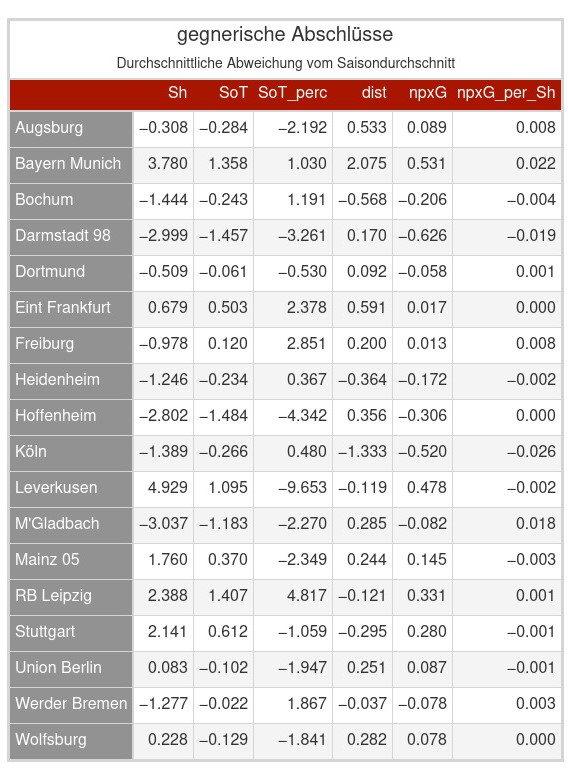
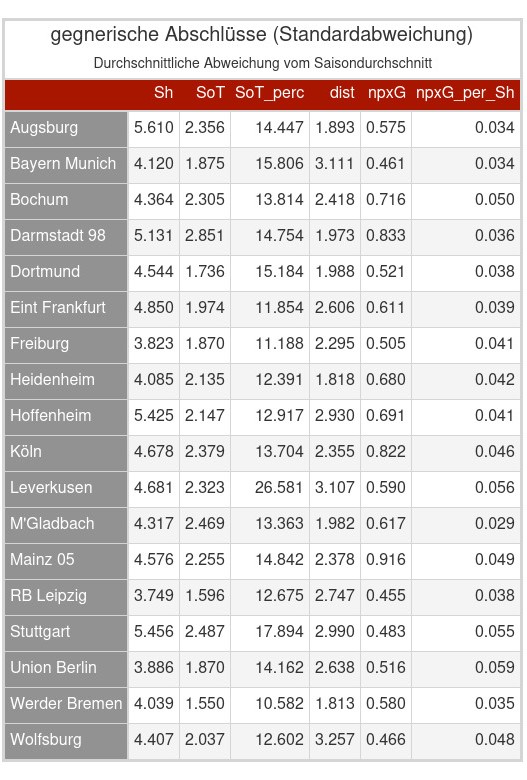
Selbiges habe ich dann auch noch für die gegnerischen Abschlüsse. Die größte Unklarheit könnte vielleicht bei der Schussdistanz liegen. Also ein positiver Wert bedeutet, dass im Vergleich zum Saisondurchschnitt der Gegner aus einer größeren Distanz abschließt. Da ich es nicht umgerechnet habe sind die Werte in Yards. (1 Yard entspricht ungefähr 0.91m) Also schließen die Bayern Gegner im Vergleich zu ihrem Saisondurchschnitt in den Spielen durchschnittlich ca 1.89m weiter weg vom Tor ab.
Zusätzlich habe ich es auch noch für andere Ballbesitzaktionen als Pässe angefertigt. Andere Ballbesitzaktionen umfassen Ballberührungen im offensiven Drittel und Strafraum aus Sicht der gegnerischen Mannschaft, Dribblings und Carries. Das einzige was nicht so direkt auf FBref zu finden ist, ist die Spalte „Dis_perc“. Die Variable bildet ab wie oft prozentual eine Mannschaft bei Carries vom Ball getrennt werden konnten. Also die 0.36 bei Leverkusen in der Spalte steht dafür, dass Gegner im Durchschnitt um 0.36% häufiger bei Carries vom Ball getrennt werden im Vergleich zum jeweiligen Durchschnittssaisonwert der Mannschaft.
Was mir direkt aufgefallen ist, dass 5 Teams positiv auffallen, da sie bei fast allen Variablen einen positiven Wert dastehen haben und damit dafür sorgen, dass ihre Gegner durchschnittlich offensiv schlechter zur Entfaltung kommen als ihr Saisondurchschnitt. Dazu gehören die Top 3 Teams (Leverkusen, Bayern, VFB), RaBa Leipzig und für einige vielleicht etwas überraschend Mainz 05.
Auf der anderen Seite fallen Darmstadt, Gladbach oder auch Werder immer wieder negativ auf.
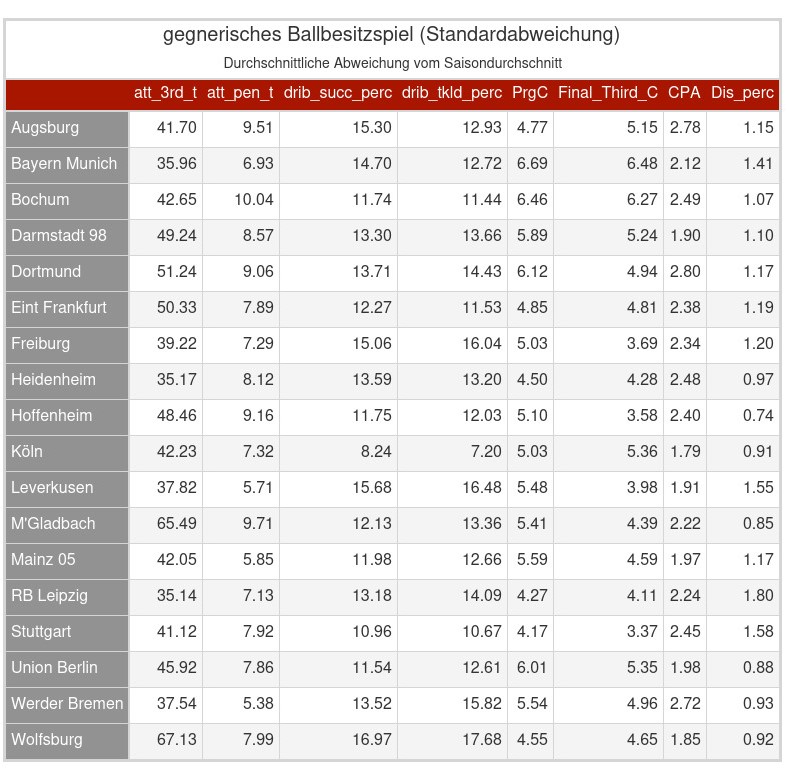
Sehr cool, vielen Dank. Hättest du noch die Standardabweichung zu den Werten? Bei Werten von 0.36% würde ich mal tippen, dass sie statistisch nicht signifikant sind, oder?
Also die Standardabweichungen hatte ich bisher noch nicht erzeugt gehabt, da es meiner Meinung nach interessanter ist sich die Werte für Einzelspiele anzusehen als auf Standardabweichungen zu gucken, da man auch mögliche Trends gegen bestimmte Teams feststellen kann. Es war aber kein wirklicher Aufwand die Standardabweichungen auch zu erzeugen. Ein Mehrwert ist sicher, dass man recht schnell ein besseres Gefühl für die Skalen bekommt. Die sind schon sehr unterschiedlich, gerade wenn ich an die gegnerischen non-penalty xG pro Schuss(npxG_per_Sh) denke und der Statistik die gegnerischen Ballkontakte im offensiven Drittel (att_3rd_t) gegenüber stelle.
Statistische Signifikanz sollte man denke ich generell nicht erwarten. Eine einzelne Saison ist dann doch in der Regel zu kurz, um sicher sagen zu können, ob mögliche Effekte nicht einfach nur Zufallseffekte sind. Ohne zu weit zu gehen, mit einer gewissen Unsicherheit muss man aber sowieso immer leben und gerade so etwas wie p-Werte vermittelt in der Regel ein Gefühl von falscher Sicherheit.
Im Nachgang zu dieser Auswertung:
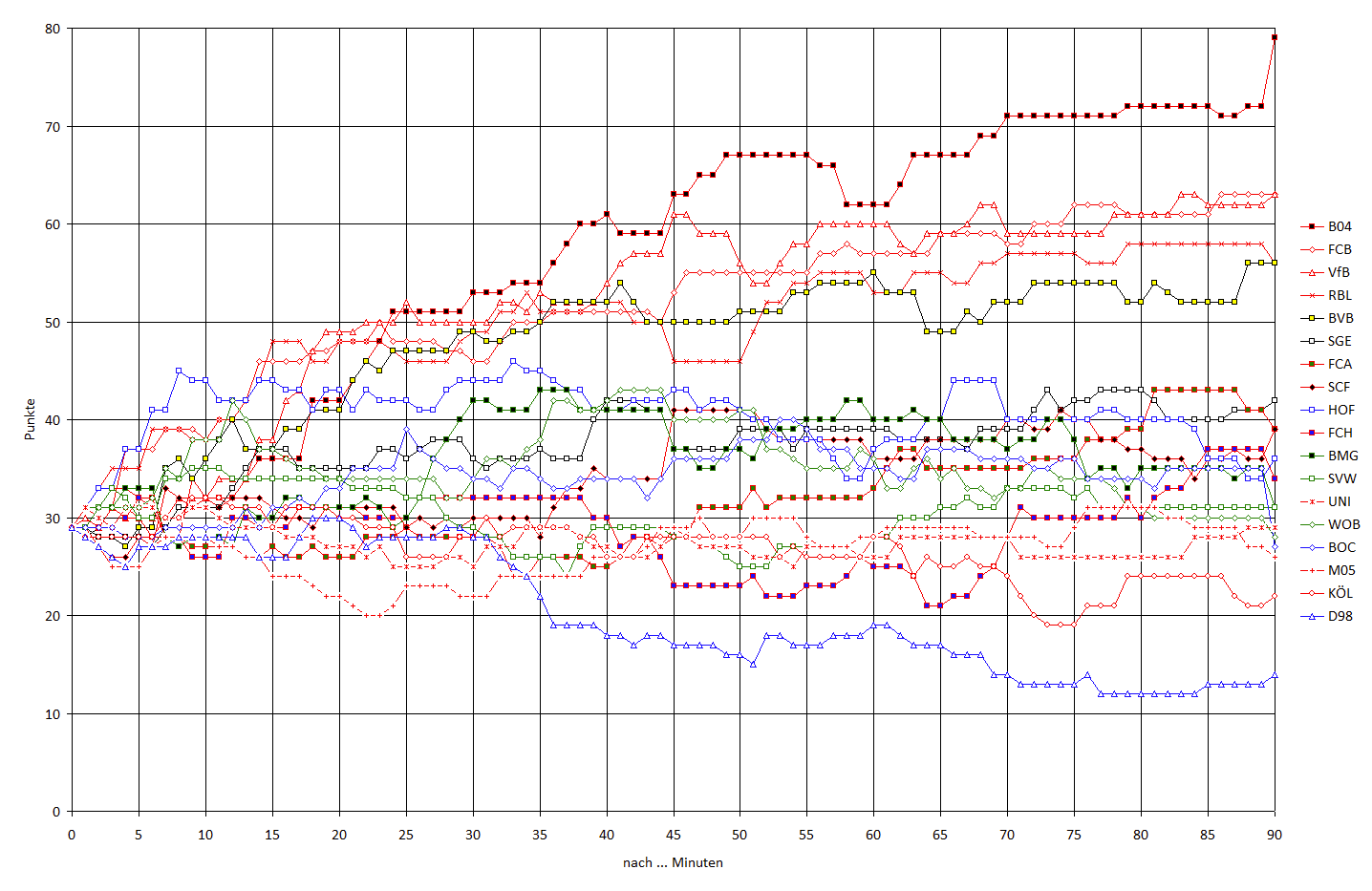
Hier die Punktzahlen basierend auf den Spielständen zu den einzelnen Spielminuten als Grafik. Ist möglicherweise nicht übertrieben gut lesbar, aber vielleicht zieht jemand interessante Erkenntnisse daraus. (Hint: Wolfsburg…)
die Idee ist auf jedenfall fantastisch. das interaktiv zum anklicken und highlighten wäre ein geiles tool.
Finde noch Hoffenheim und Heidenheim spannend. Hoffenheim macht anscheinend in den ersten minuten punkte und stellt dann das spielen ein und heidenheim sollte überlegen wie sie besser aus der pause kommen.
Gibt es da irgendein (bestenfalls niedrigschwelliges) Framework, mit dem man sowas erzeugen und idealerweise direkt hier einbinden könnte? Die zugrundeliegenden Daten sind ja ziemlich überschaubar, aber das ist ein Bereich, wo ich mich praktisch gar nicht auskenne…