Für die etablierten Bundesligisten eine interessante Statistik. Beim Abstieg gerät das Modell aber an seine Grenzen. Paderborn, Düsseldorf und Bielefeld nutzt ihr guter Wert und die vordere Position in der Tabelle wenig. Die Frage ist, ob sie mit dem Einsatz von mehr Geld den Klassenerhalt erreicht hätten. Wenn nicht, hätten sie zwar individuell alles richtig gemacht, aber für die Statistik ist ein Abstieg der schlechteste Fall.
Joa, da hast du natürlich Recht. Das Modell gilt natürlich nicht für die Extremfälle, wobei ich das noch nicht ganz verwerfen würde. Paderborn, Düsseldorf und Bielefeld haben für ihre Möglichkeiten überperformt, sonst wären sie ja nie in die Bundesliga aufgestiegen… und sie verlernen (meistens) ja nicht von heute auf morgen wie es geht. Das ist quasi schon Auslese-bias mit drin. Aber am Ende hat es dennoch nicht gereicht auch wenn sie sich tapfer geschlagen haben.
Das ist aber nicht immer der Fall, siehe Nürnberg, die haben noch nicht mal das erwartbare rausgeholt und sind 2019 mit 19 Punkten sang- und klanglos untergegangen.
Hot take dazu: Tordifferenz und Punkte.
Klar kann das unter Umständen einen Einblick geben in spielt ein Team eher offensiv all out oder eher minimalistisch auf knappe Siege bedacht. Aber vor allem sagt mir das wie erfolgreich ein Team spielt und das ist doch letztendlich das was zählt. Ob ich da jetzt mit Simeone-Fußball oder mit Klopp-Fußball hinkomme ist dann erst in zweiter Linie interessant. Das allerwichtigste für mich wenn ich wissen möchte „wie spielt ein Team“ ist „was kommt am Ende dabei rum“, schließlich ist Taktik ja kein Selbstzweck.
Klar, Taktik ist kein selbszweck, aber Punkte und Tordifferenz kann ich einfach in der Tabelle ablesen ![]() Ich will ja explizit nicht wissen wie erfolgreich ein Team spielt sondern mit welchem Ansatz er versucht dies zu tun. Kann am Ende auch fürchterlich daneben gehen. Und Tordifferenz sagt mir noch nicht einmal ob sie alle Spiele 5:4 oder 1:0 gewinnen
Ich will ja explizit nicht wissen wie erfolgreich ein Team spielt sondern mit welchem Ansatz er versucht dies zu tun. Kann am Ende auch fürchterlich daneben gehen. Und Tordifferenz sagt mir noch nicht einmal ob sie alle Spiele 5:4 oder 1:0 gewinnen
Wenn es nicht auf FBref beschränkt wäre, würde ich von The Analyst PPDA und Direct Speed auswählen. Dann hätte ich jeweils eine statistischen Wert für die Defensive wie auch Offensive. Zum einen hat man mit PPDA eine Idee, ob die jeweilige Mannschaft probiert früher draufzugehen oder die Tendenz doch eher ist sich zurückzuziehen und im tieferen Block zu verteidigen. Andererseits zeigt einem die Direct Speed Statistik, ob eine Mannschaft im Ballbesitz einen direkteren oder geduldigeren Ansatz wählt. Dann hat man meiner Meinung nach schon eine ganz gute Idee wie eine Mannschaft spielt, dementsprechend würde ich versuchen die beiden Werte mit FBref Statistiken nachzubauen. Das eine Beispiel mit Progressiv Passing Distance / Total Passing Distance passt als Alternative zum Direct Speed schon ganz gut und sollte vermutlich nicht groß davon abweichen. Etwas mehr Unschärfe bekommt man beim Ersatz für PPDA rein, da FBref nicht für alle defensive Aktionen aufgliedert, wo sie passieren. Dasselbe gilt übrigens auch für Pässe. Pässe könnte man theoretisch mit Ballkontakten ersetzen, wobei die werden bei der räumlichen Aufteilung jeweils in jedem Bereich gezählt. Wenn also ein Spieler den Ball im defensiven Drittel bekommt, ins mittlere Drittel trägt und dann erst abspielt, zählt es fürs defensive und mittlere Drittel als Ballkontakt. Die Summe der Ballkontakte in den Bereichen übersteigt schlussendlich deutlich die Gesamtanzahl an Ballkontakten. Einfacher ist es sich nur auf die Tackles zu beschränken. Mein Ersatz für PPDA sieht dann wie folgt aus: (Tackles Mid 3rd + Tackles Att 3rd) / Tackles.
2 „Gefällt mir“
dein Name ist Programm, tausend Dank
Fußball: Wer sind die Freunde und Rivalen Ihres Lieblingsvereins? - DER SPIEGEL
Interessante Statistiken vom Spiegel aus 2018
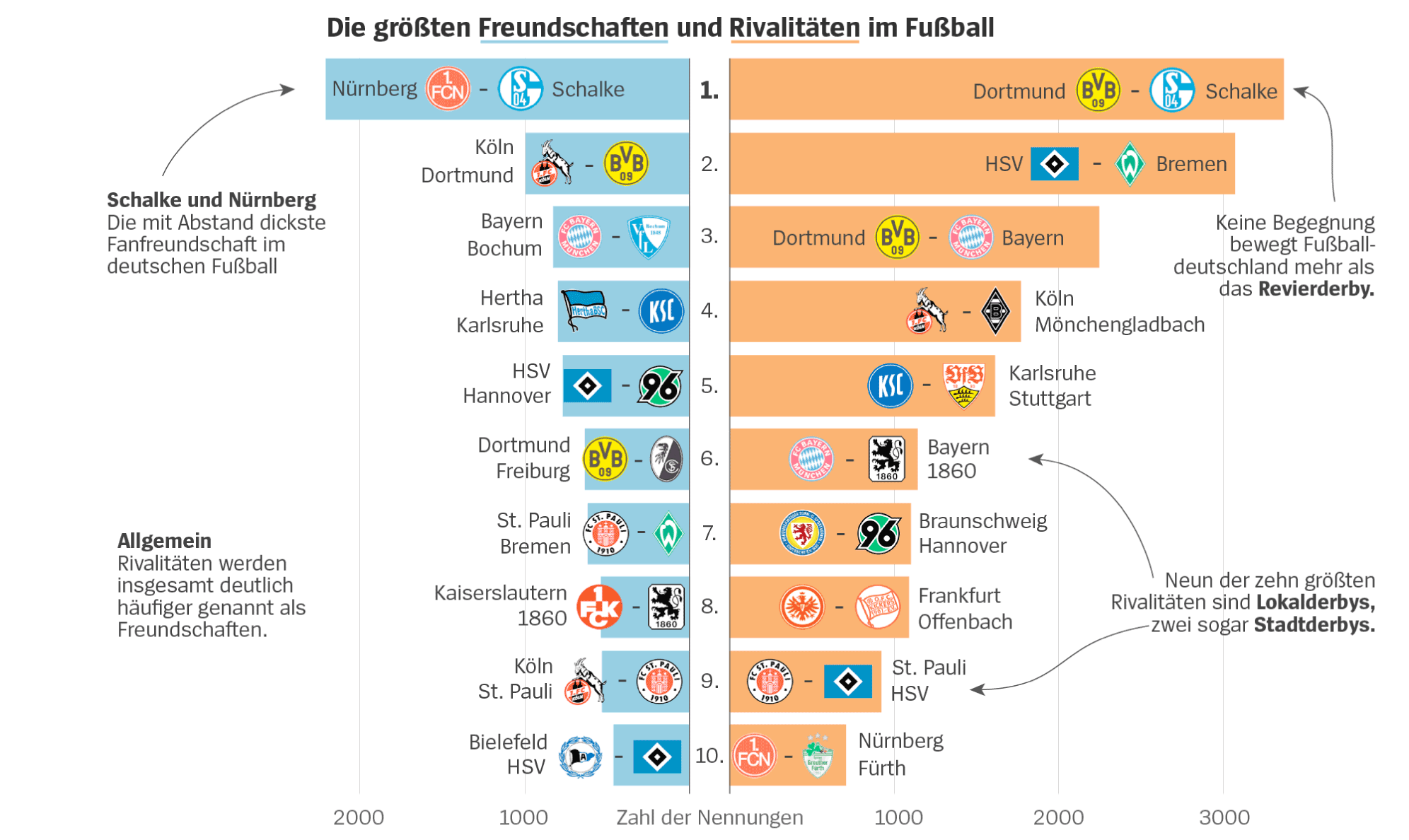
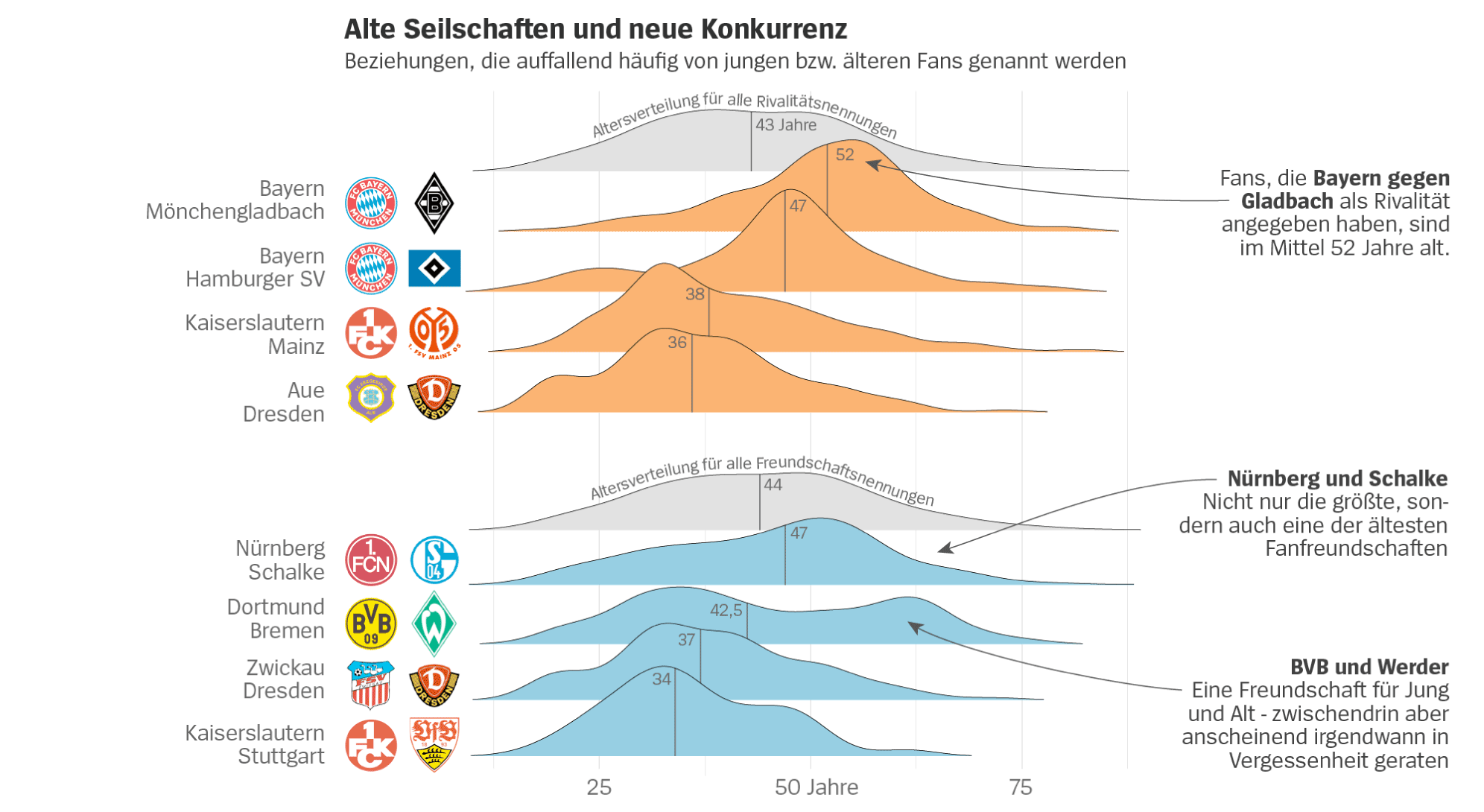

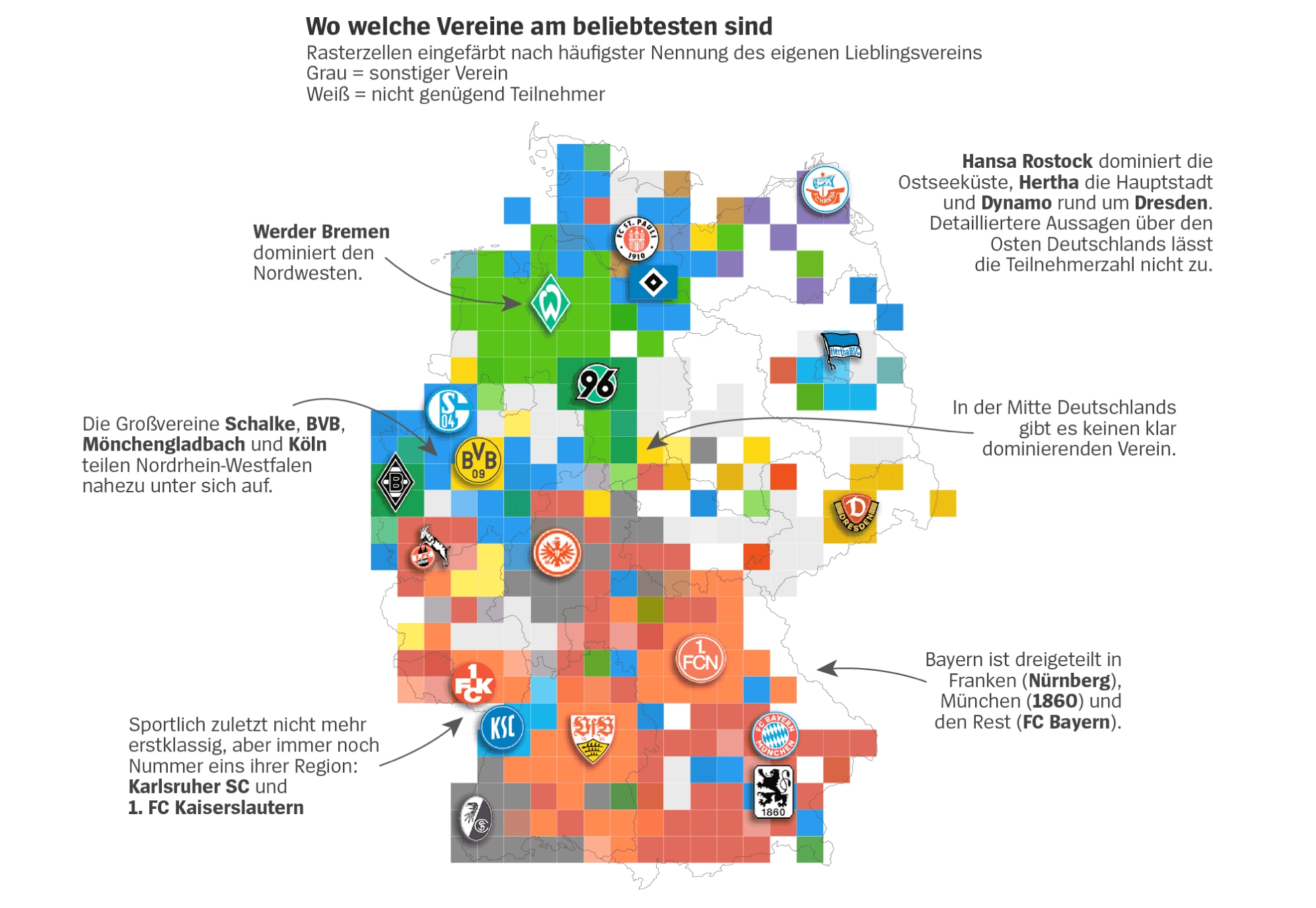
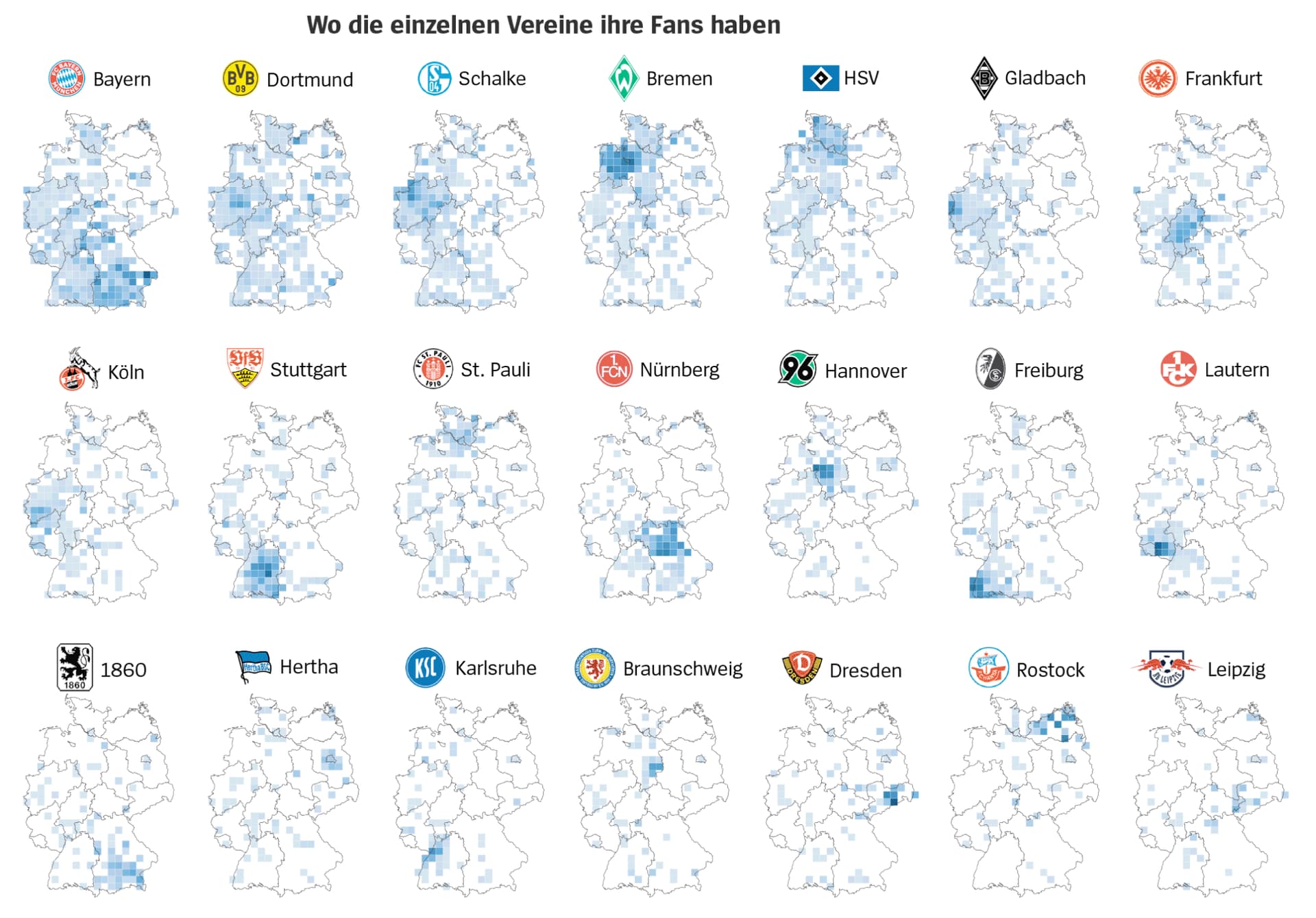

3 „Gefällt mir“
Zum Mythos „das zweite Jahr ist das schwerste“ die Aufsteigerbilanz der zehn Saisons von 2011/12 bis 2020/21 (um Raba bereinigt, da es sich um ein durchfinanziertes Planprojekt handelt und nicht um einen normalen Aufsteiger):
- von den insgesamt 21 Aufsteigern sind 7 direkt in der ersten Saison wieder abgestiegen (33% Abstiegsquote, Durchschnittsplatzierung 13,2)
- von den verbleibenden 14 Aufsteigern sind weitere 6 in der zweiten Saison abgestiegen (43% Abstiegsquote, Durchschnittsplatzierung 14,7)
- von den verbleibenden 8 Aufsteigern sind 0-1 (je nachdem was diese Saison mit Bochum passiert) in der dritten Saison abgestiegen (0% Abstiegsquote, Durchschnittsplatzierung 7,7!)
- von diesen 8 Aufsteigern, die es in die dritte Saison geschafft haben, sind bisher überhaupt nur Köln (in der vierten Saison) und Hertha (in der zehnten Saison) wieder abgestiegen
Tatsächlich ist also die zweite Saison um 1,5 Plätze schwieriger als die erste Saison, allerdings aufgrund des kleinen Datensatzes nicht wirklich signifikant genug um eine klare Aussage zu treffen. Weiter zurück gehen wollte ich allerdings auch nicht, weil sich die Bundesliga im letzten Jahrzehnt zu sehr verändert hat, als dass die Zahlen der frühen 2000er den Datensatz wirklich aufwerten würden.
Festhalten lässt sich denke ich die Schlussfolgerung „die ersten beiden Saisons sind für einen Aufsteiger am schwersten, danach hat man sich etabliert“.
6 „Gefällt mir“
Wie stark ändern sich die effektiven Kader?
Wegen des Union Schwerpunktes war ich mal interessiert, wie sehr sich die Kader der Vereine effektiv ändern im Laufe der Jahre. „Effektiv“ soll an dieser Stelle heißen, dass vorallem die gespielten Minuten eine Rolle spielen soll und nicht nur wie sich die Bank ändert.
Dafür habe ich für die letzten sechs Saisons und die aktuell laufende (also 2017/18 bis 2023/24) bei FBref die gesamt gespielten Minuten der Spieler genommen und daraus die Überschneidungen zwischen zwei Saisons berechnet.
Die Methodik ist etwas kompliziert diesmal und ich habe sie hier aus reinem Pflichtbewusstsein mit aufgeschrieben, ihr müsst sie aber nicht lesen. Am Ende ist sie auch Wurst, es fällt jedenfalls ein Wert raus der (mMn) ein relativ gutes Maß dafür ist wie sehr sich der „effektive“ Kader von einer Saison auf die nächste verändert hat.
Methodik – sehr(!) technisch dieses Mal
Für jeden Spieler P eines Clubs wird dessen totale Spielzeit tP,s für die Saison s genommen und dann durch die Gesamtminuten (ΣP tP,s) des kompletten Kaders geteilt. Die Quadratwurzel aus diesem normierten Wert wird dann als τP,s definiert:
τP,s² = tP,s / ΣP tP,s
Um jetzt zu wissen wie groß die Überschneidung zwischen den gespielten Minuten einer Saison s und der vorherigen Saison s-1 ist, muss man für jeden Spieler den Wert τP der beiden betrachteten Saisons multiplizieren. Über den ganzen Kader aufsummiert ergibt das dann die tatsächliche Überschneidung Q
Qs,s-1 = ΣP τP,s τP,s-1
Die Physiker unter euch werden gemerkt haben, dass ich mir einfach einen Hilbertraum aufgezogen und den Überlapp der „Wellenfunktion“ berechnet habe:
|ψs❭= ΣP τP,s |P❭
Qs,s = ❬ψs|ψs❭= 1
Qs,s-1 = ❬ψs|ψs-1❭
Die „Änderung“ von eine Saison auf die nächste ist dementsprechend einfach
1-Qs,s-1
Damit man auch einen Vergleichswert hat habe ich noch einen Mittelwert gebildet aus allen Vereinen, die im ausgewählten Zeitfenster dauerhaft Bundesliga gespielt haben [1]. Auf- und Absteiger verändern ja durchaus häufiger ihren Kader (vorallem Absteiger wie man nachher sieht), daher sind die nicht mit in den Mittelwert eingeflossen.
Als Beispiel hier einfach mal Leverkusen:
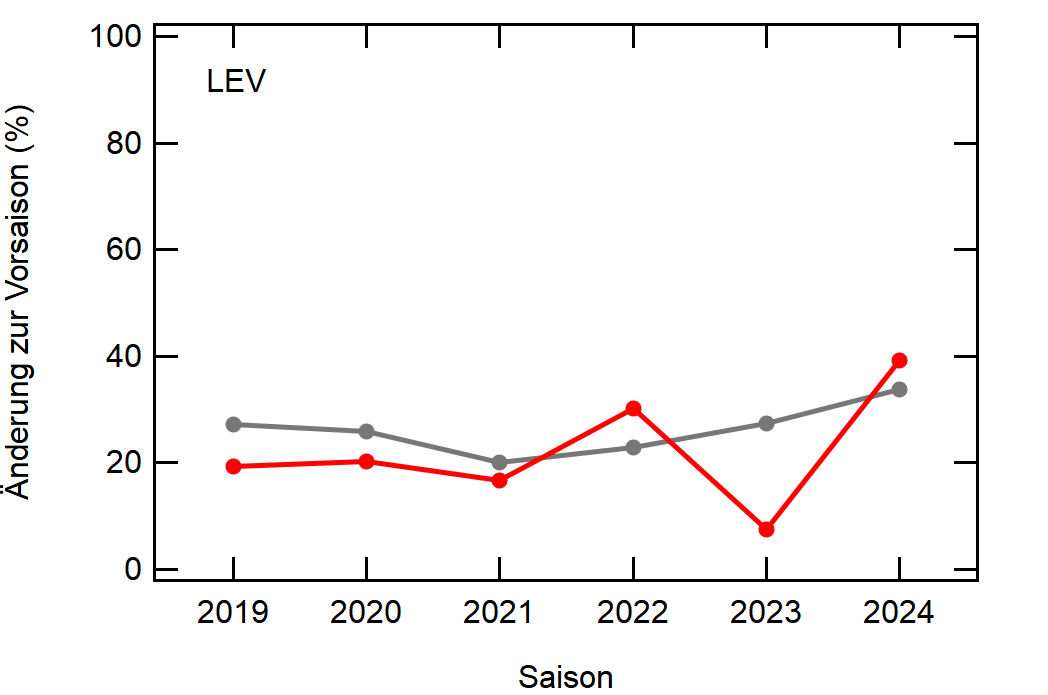
In grau sehen wir den Mittelwert, welcher sich relativ konstant um die 30% bewegt. Zu Corona gab es einen kleinen Knick nach unten, da der Transfermarkt doch etwas eingeschlafen ist (würde ich so deuten), aber danach ging es wieder hoch, vlt um die verpassten Kaderumbauten nachzuholen.
Leverkusen in rot dagegen bewegt sich als stabiler Bundesligist in etwa rund um den Mittelwert auf, mit einem krassen Dip in der Saison 2022/23, wo man quasi mit dem komplett identischen Kader wie 2021/22 gespielt hat.
Hier noch die Graphen für alle Vereine die seit der Saison 2017/18 mal Erste Bundesliga gespielt haben:
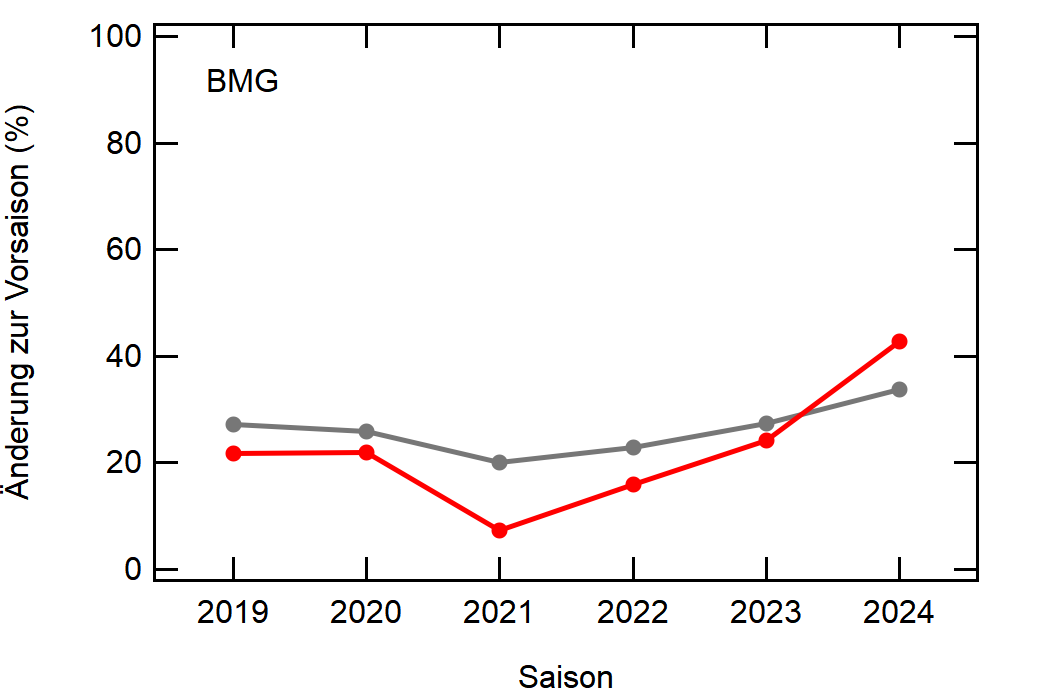
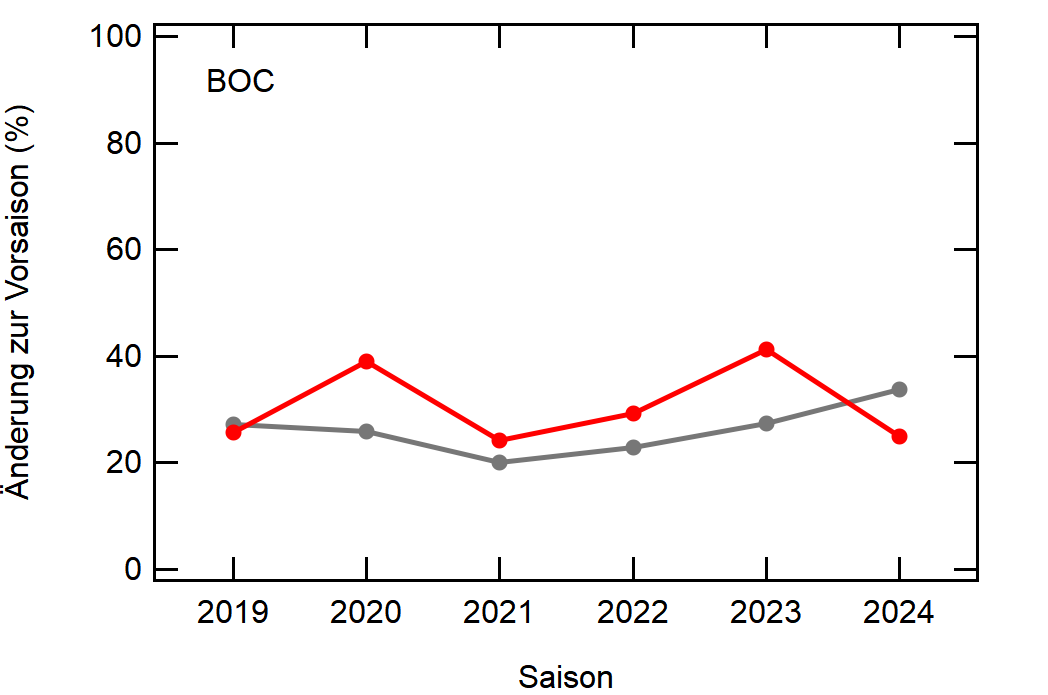
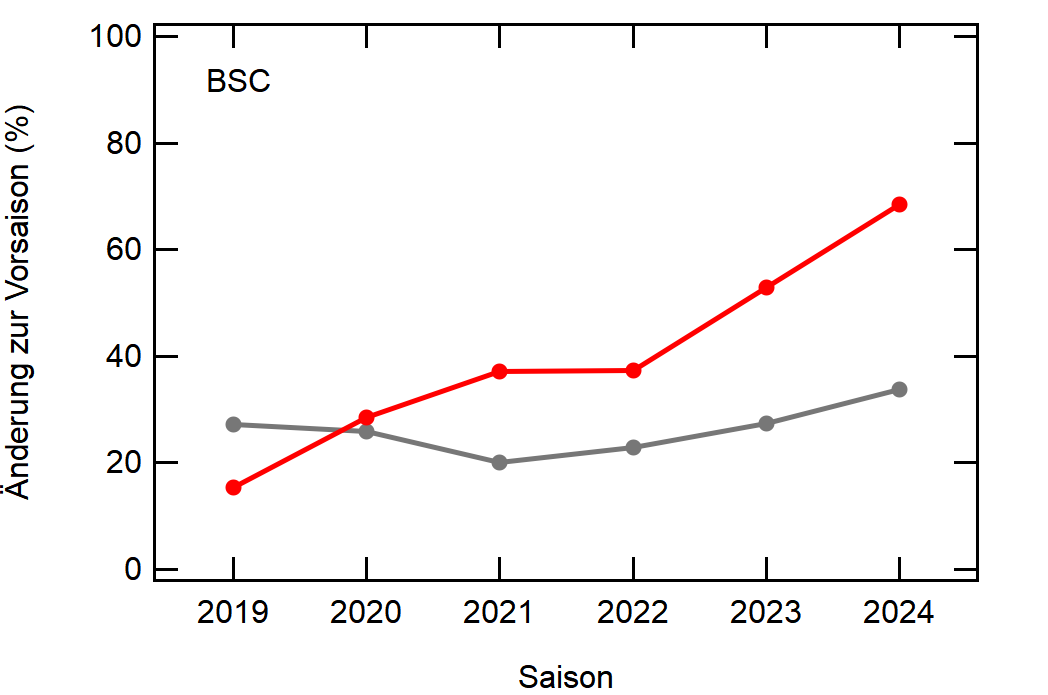
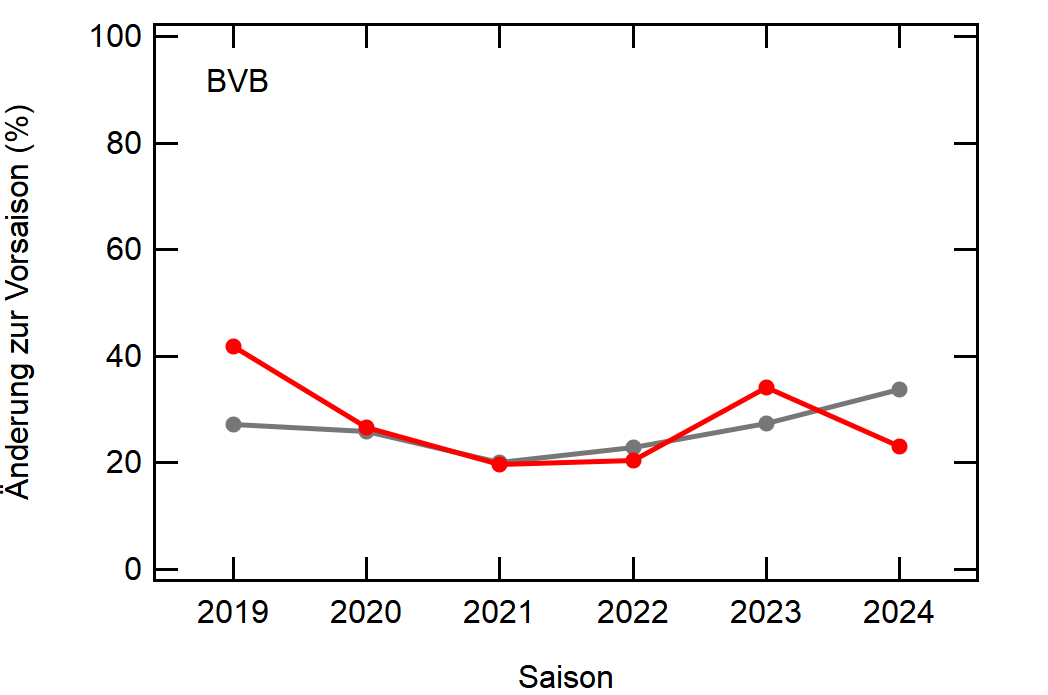
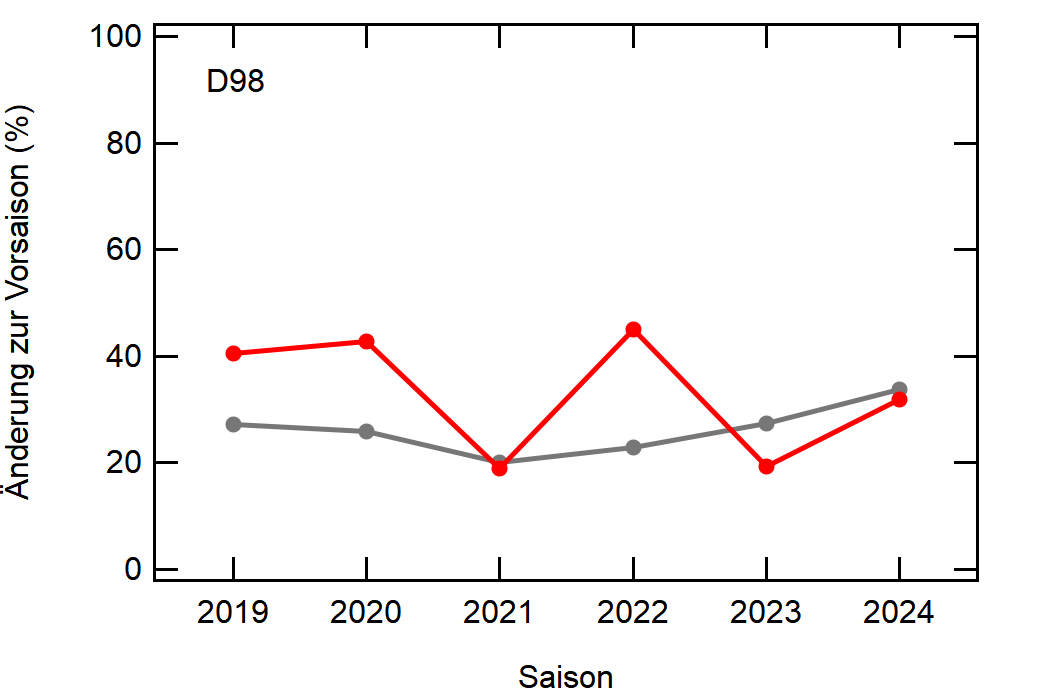
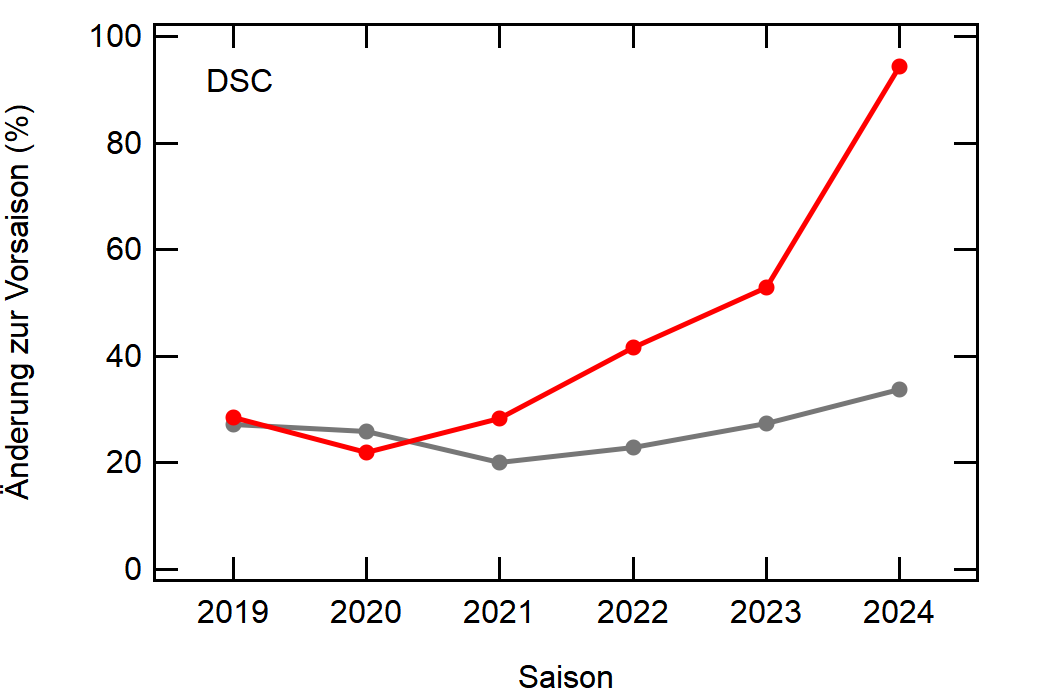
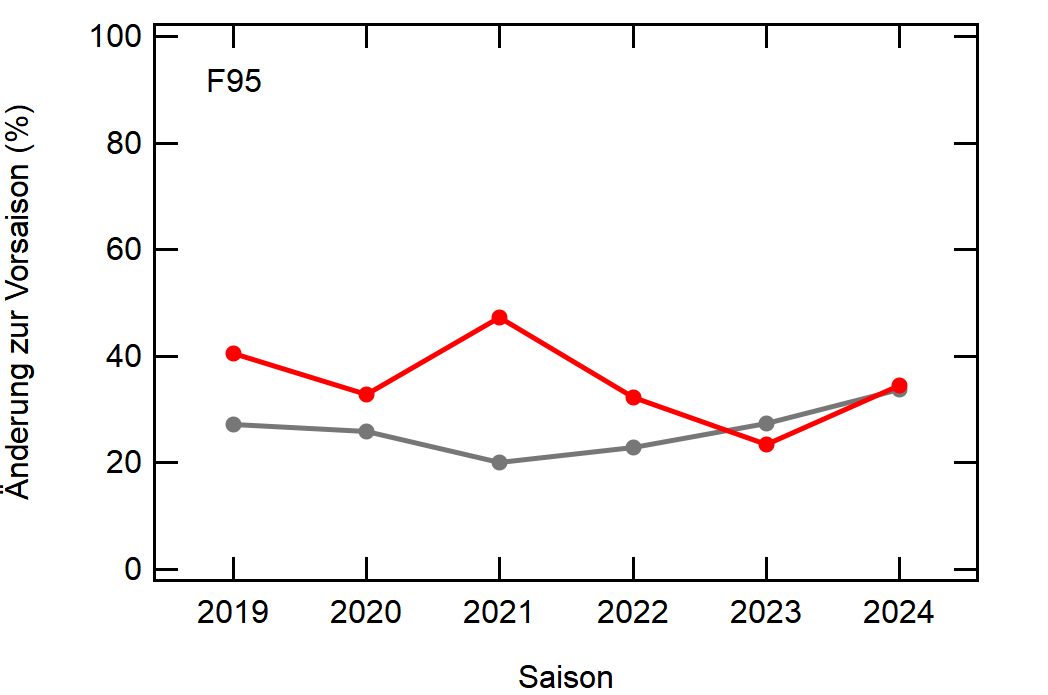
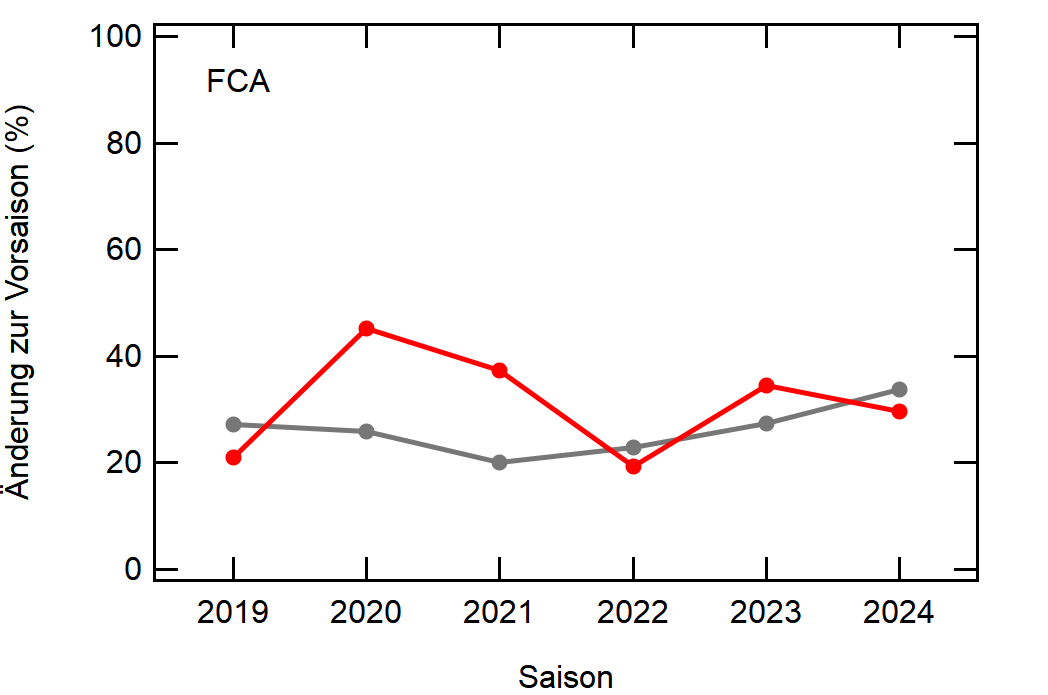
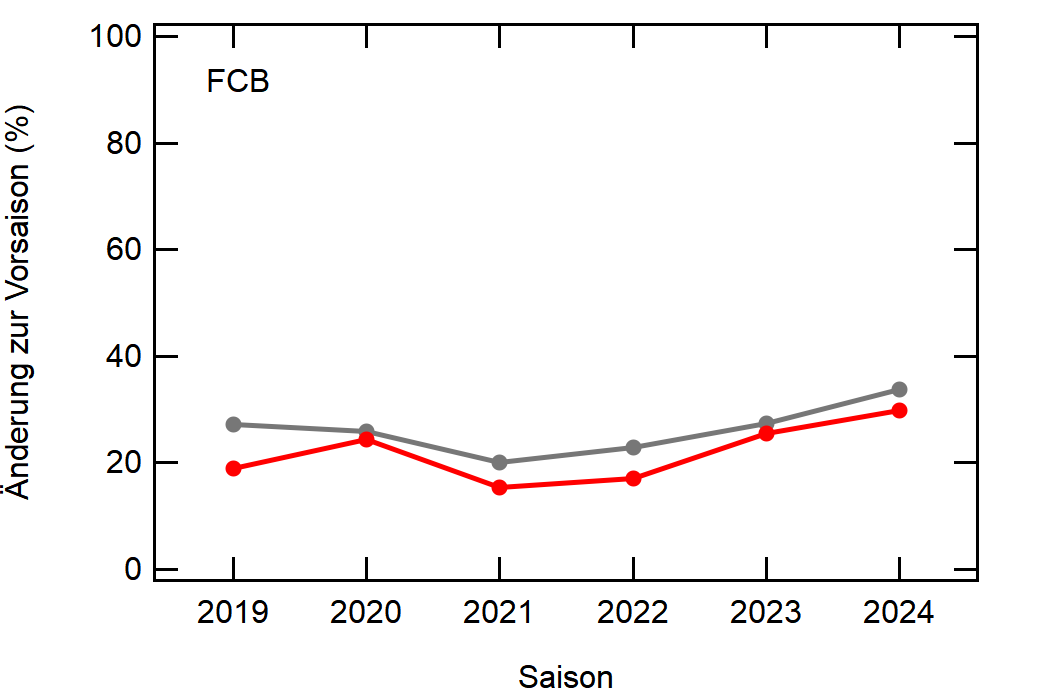
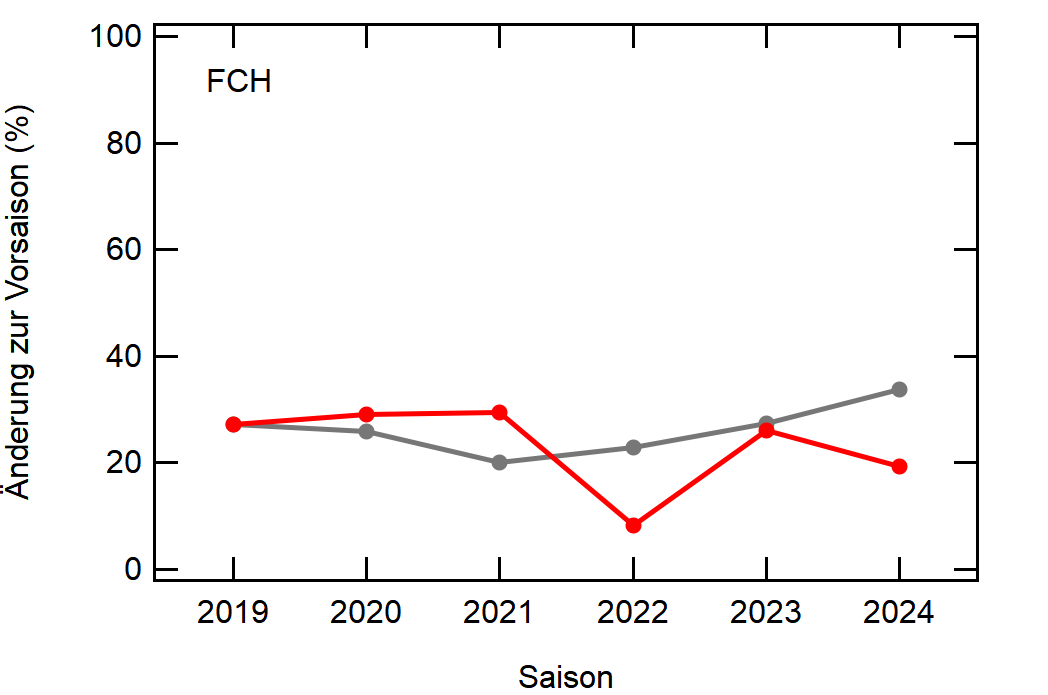
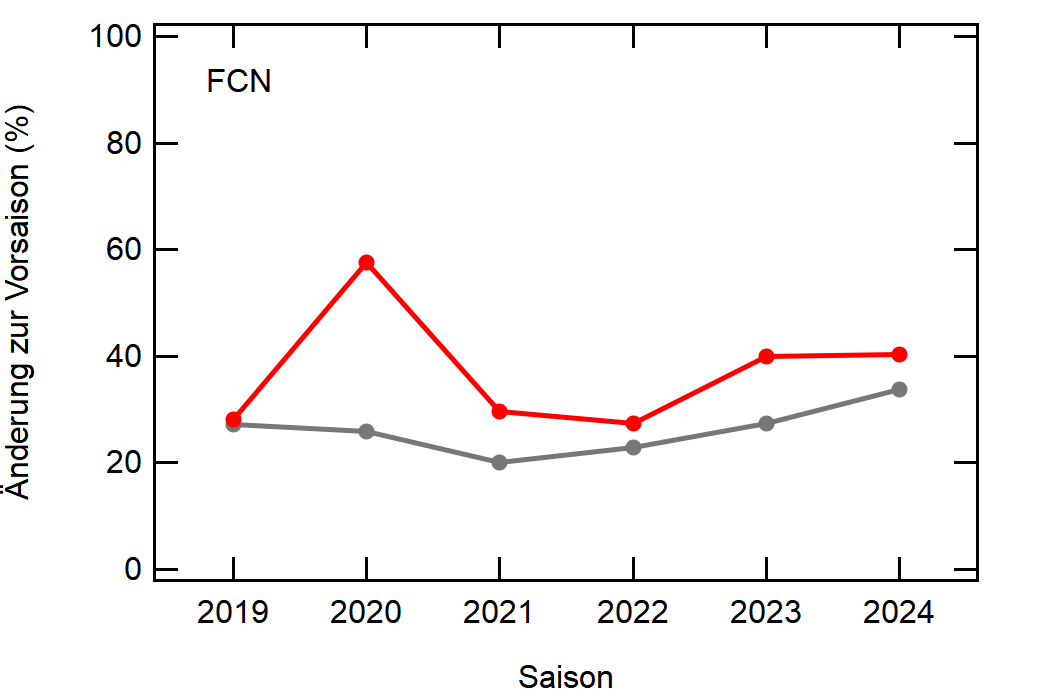
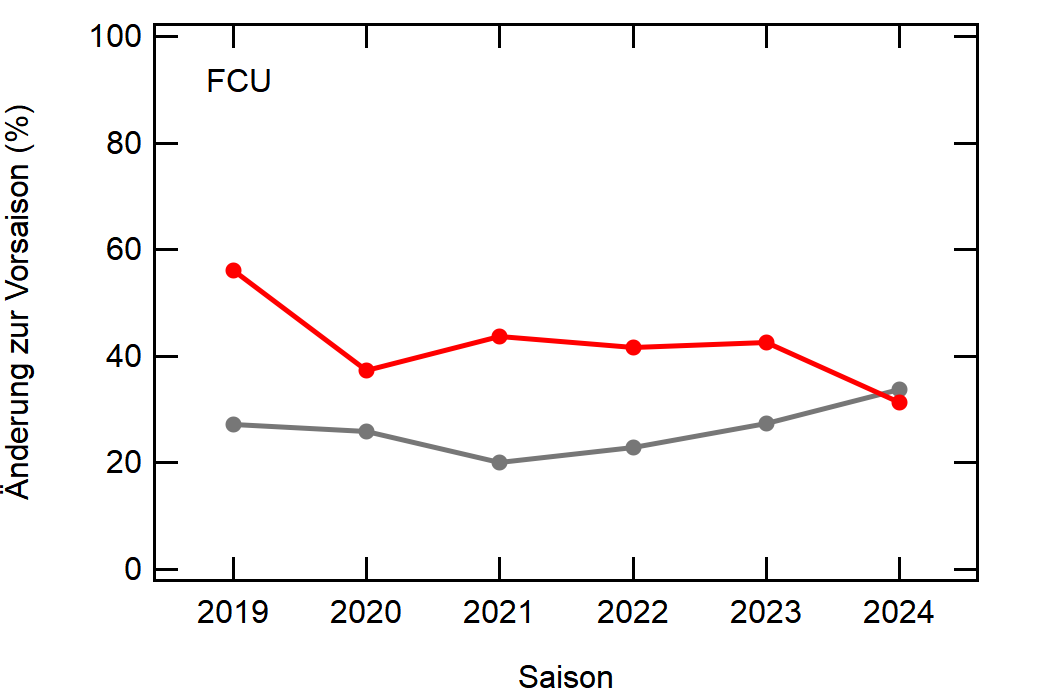
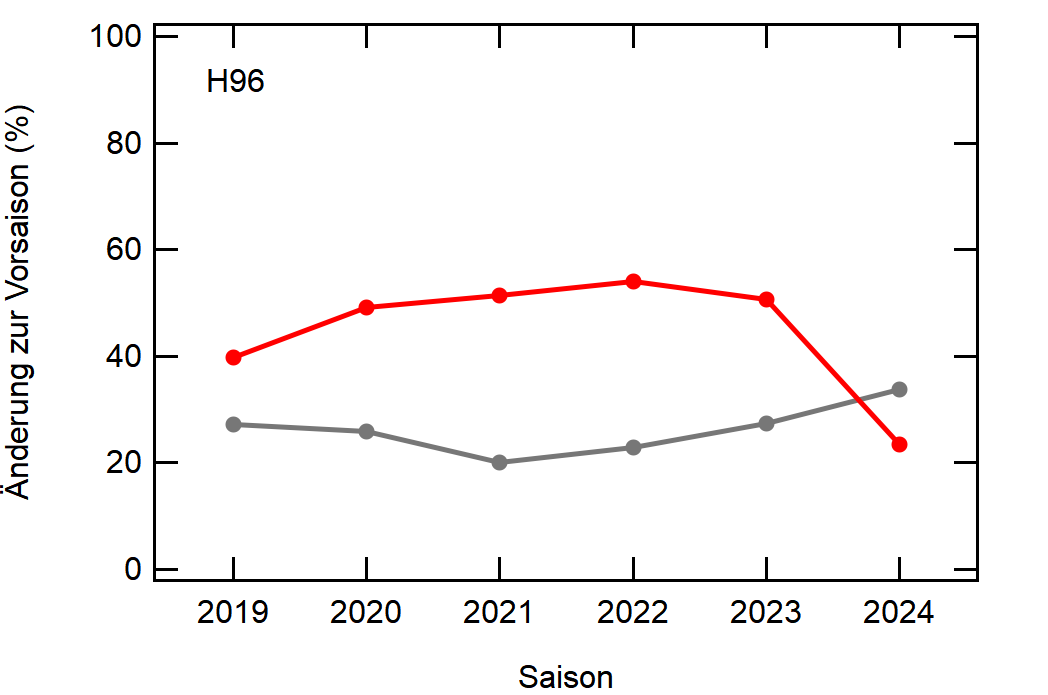
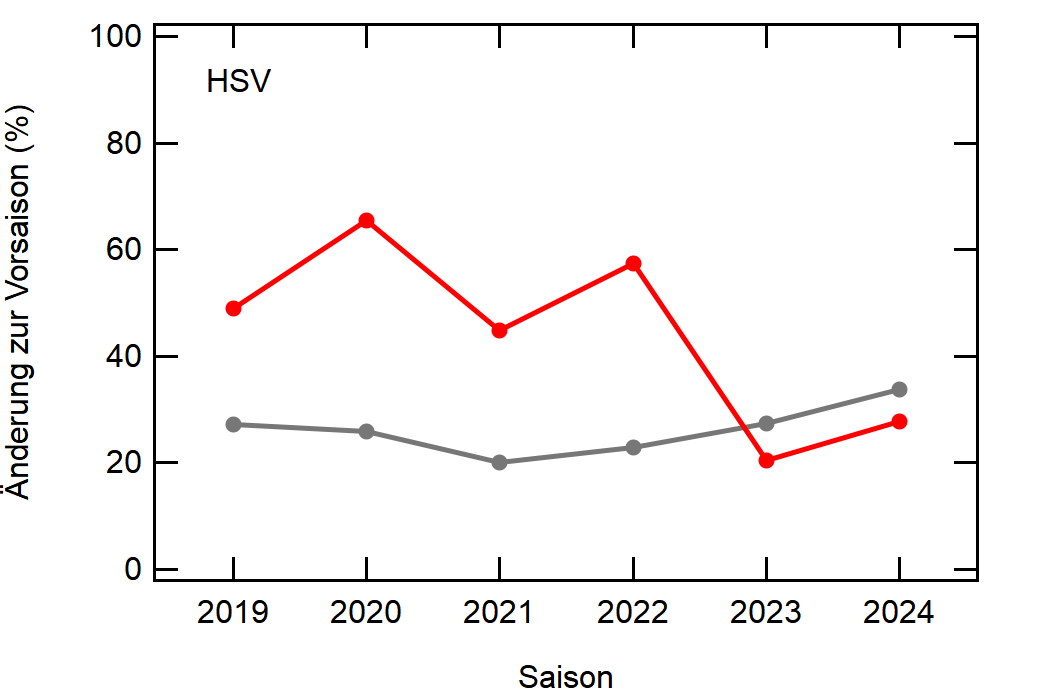
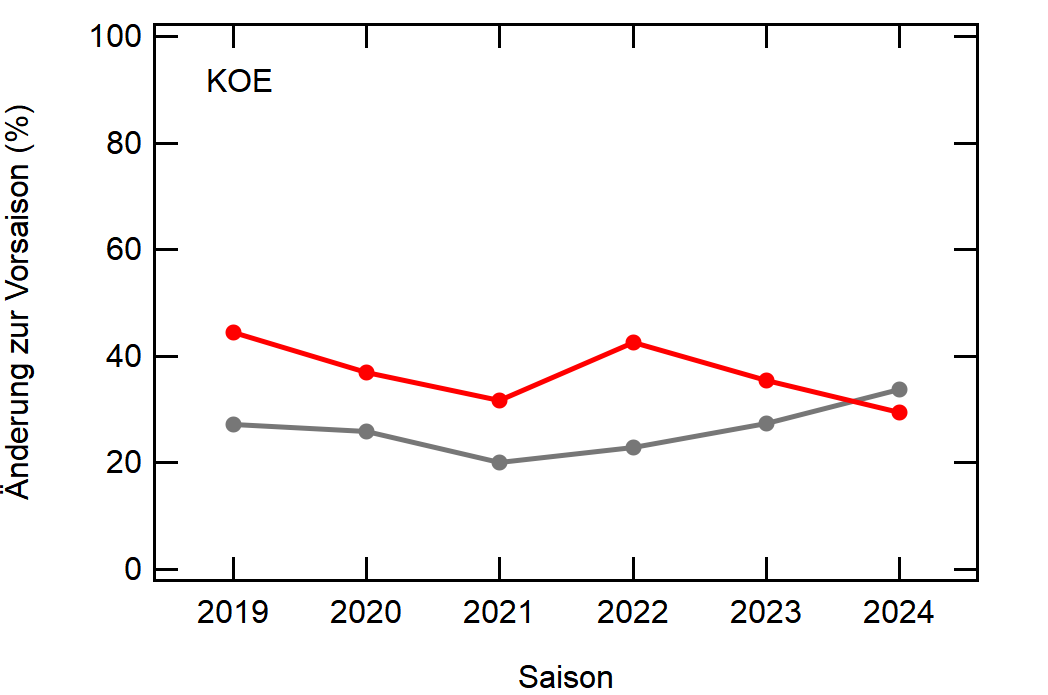
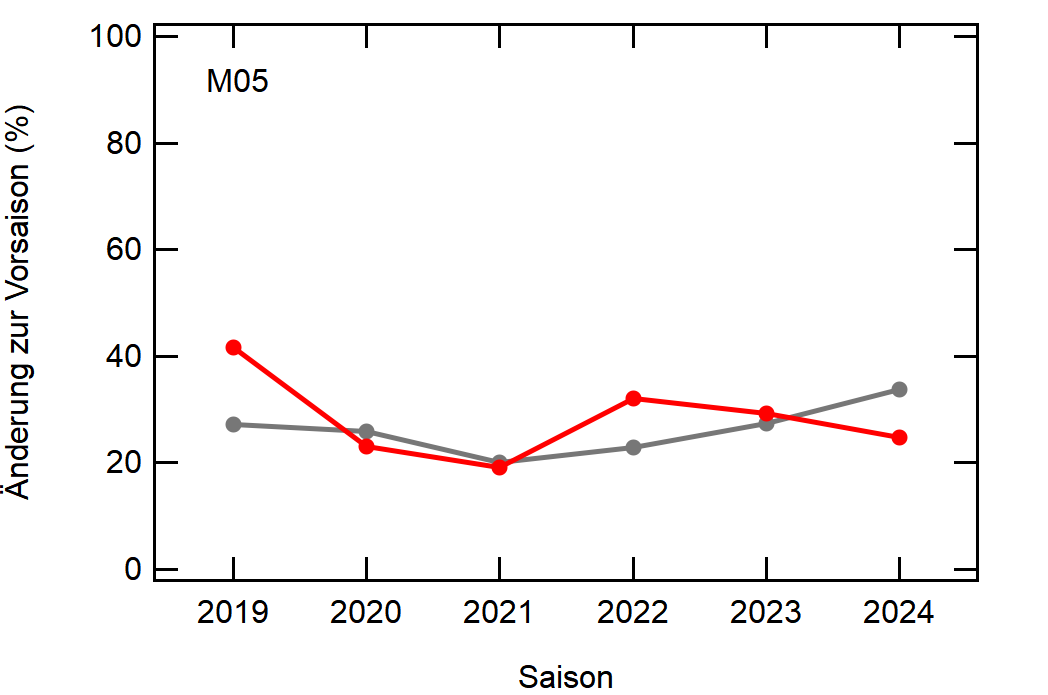
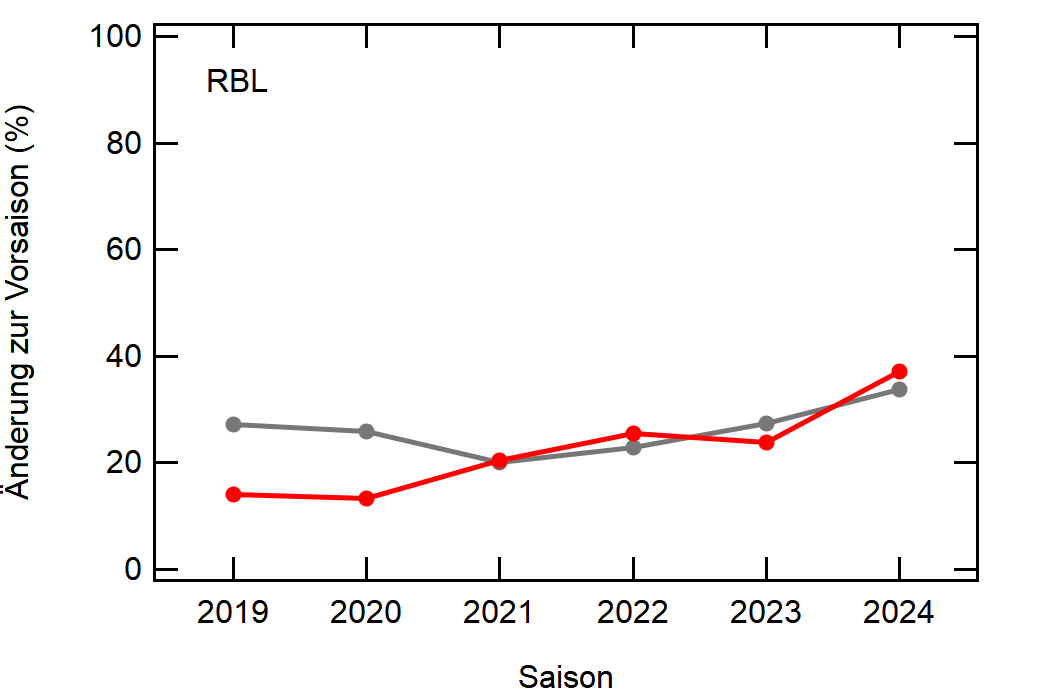
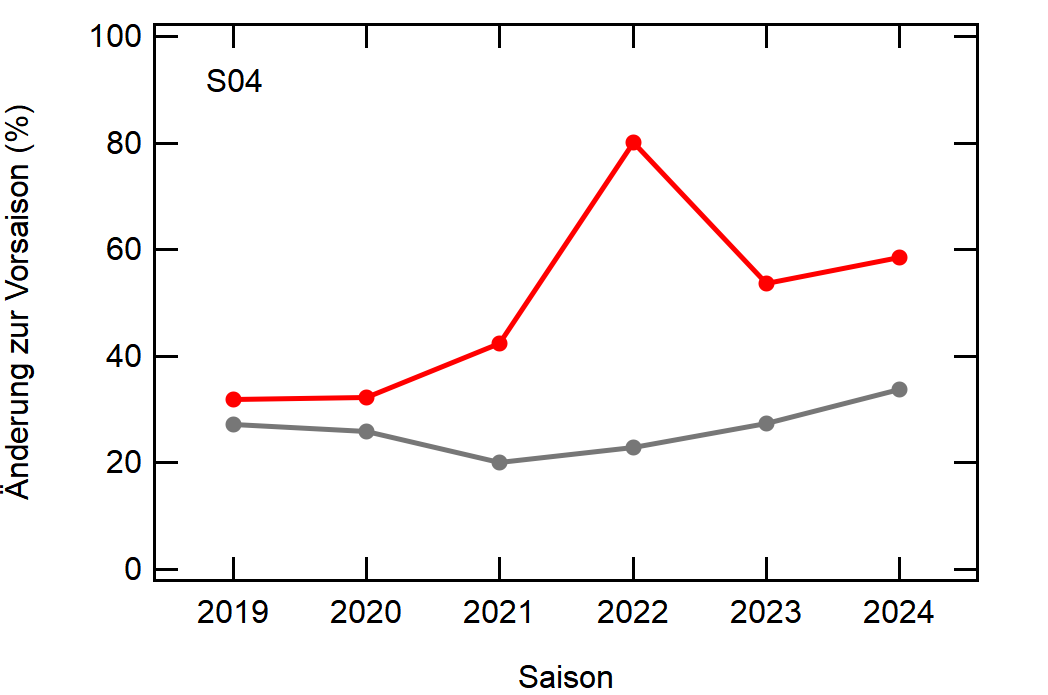
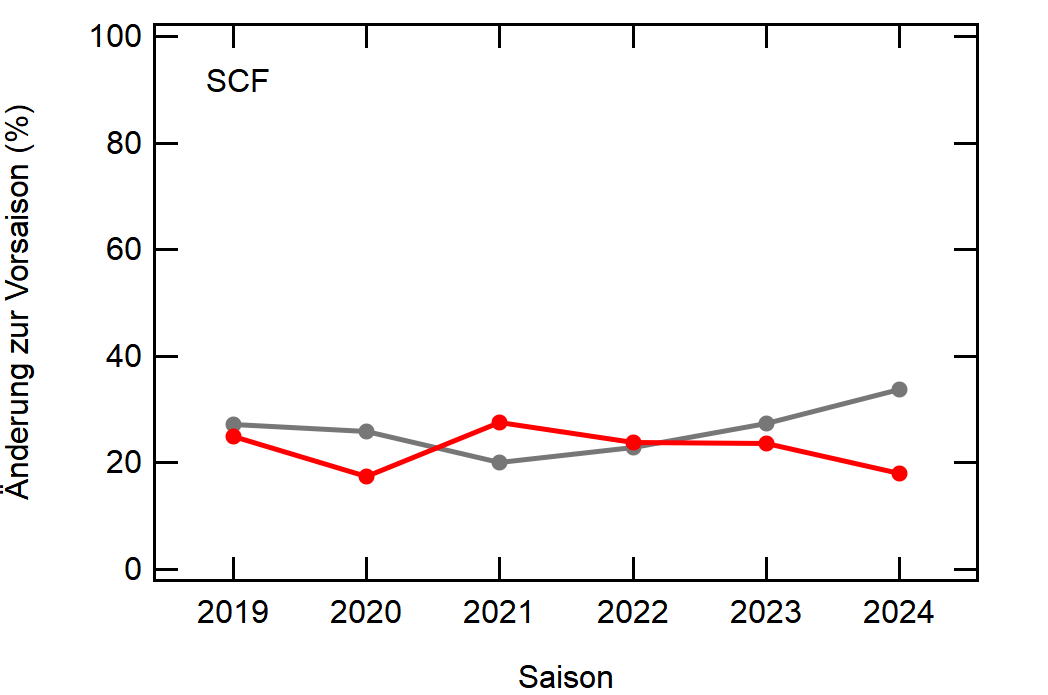
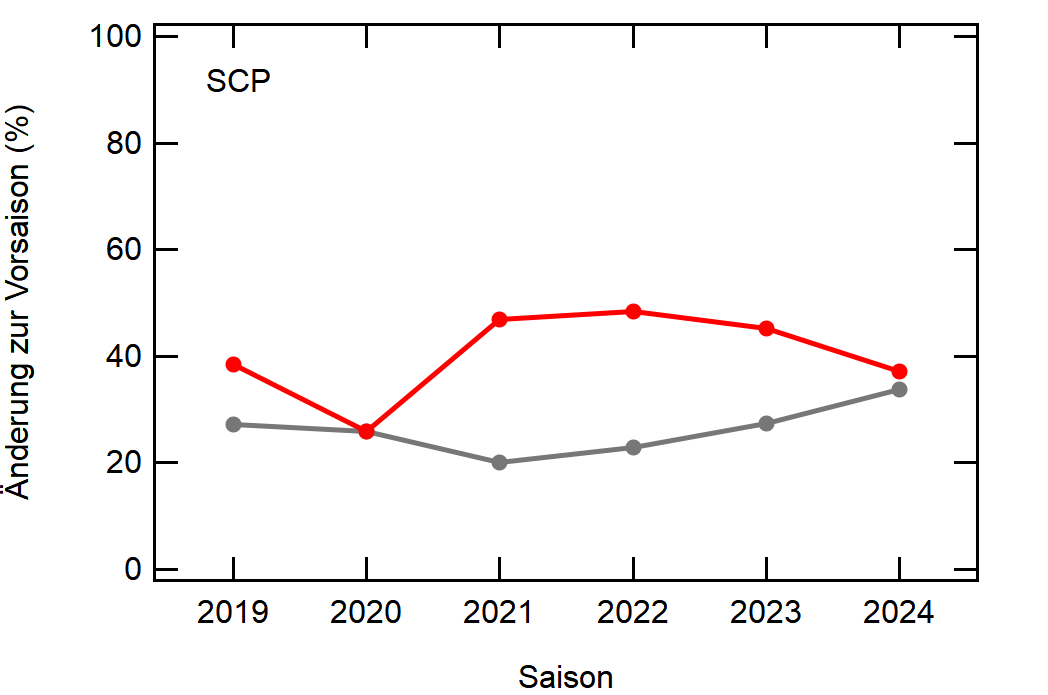
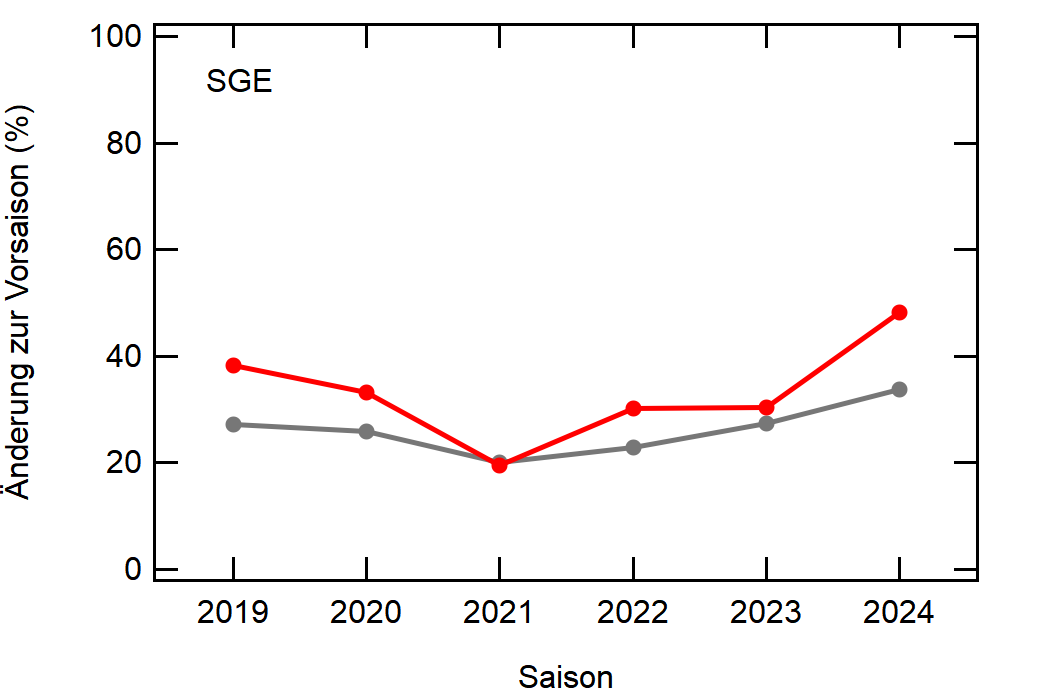
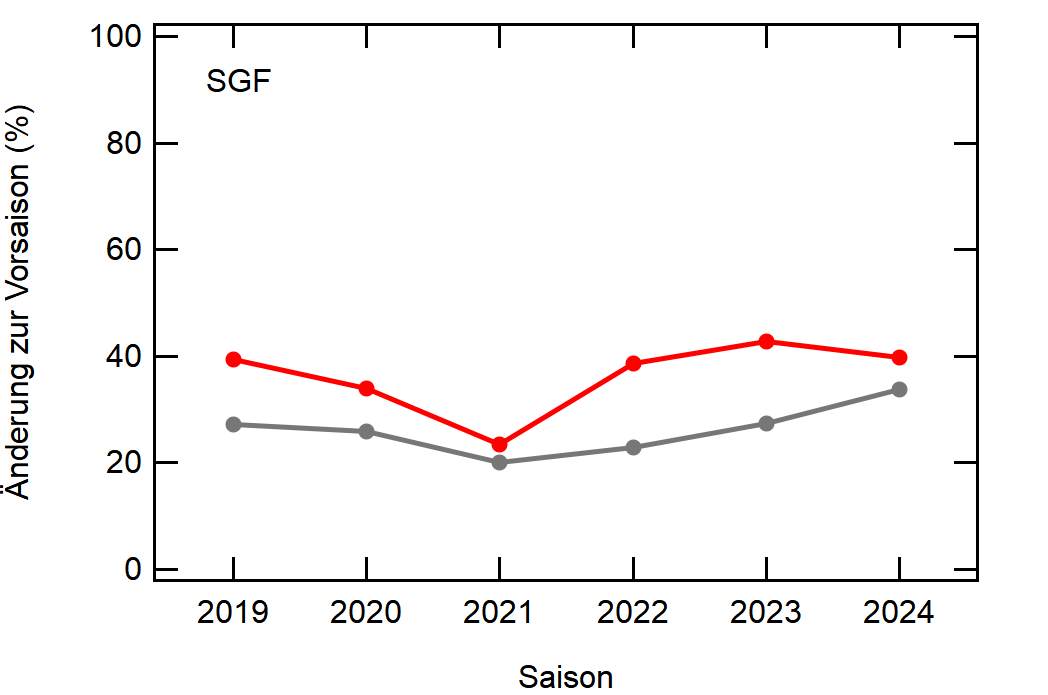
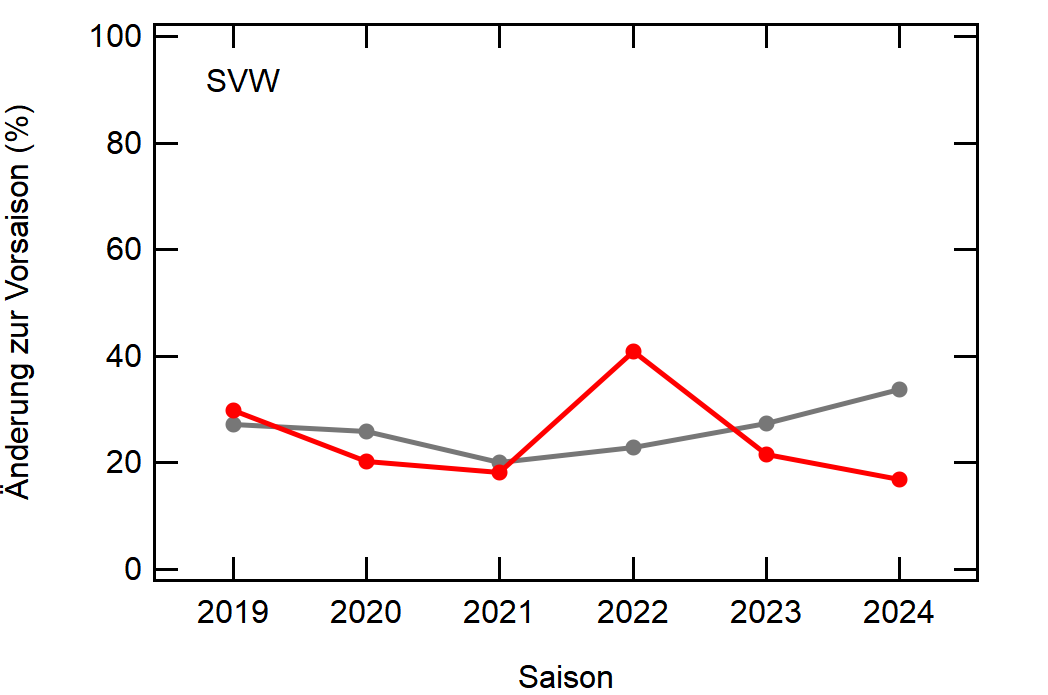
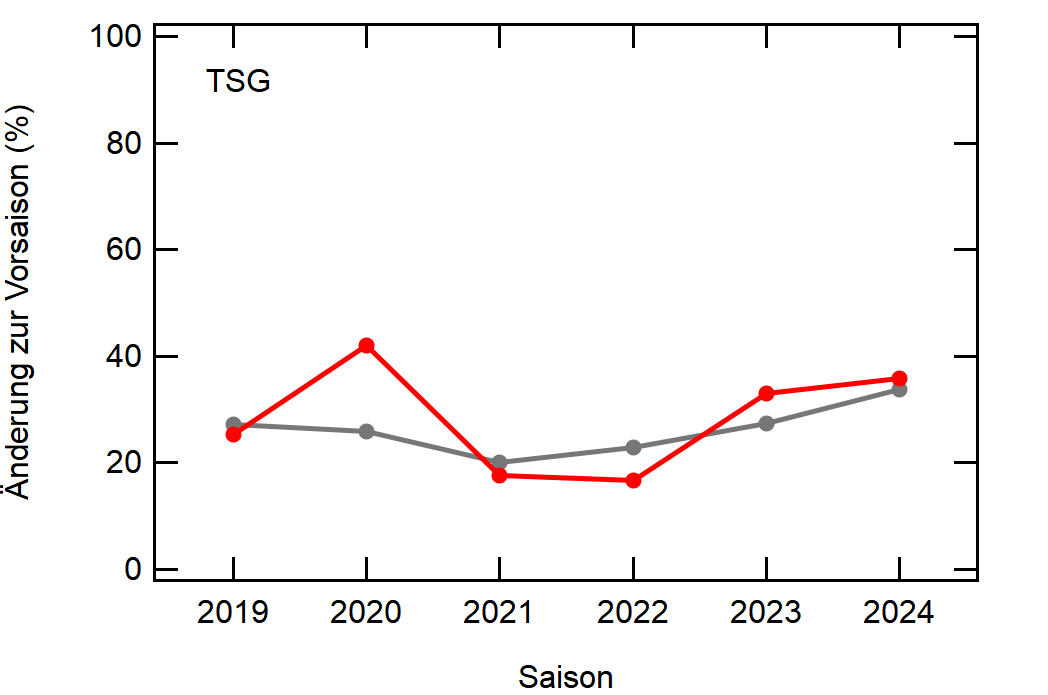
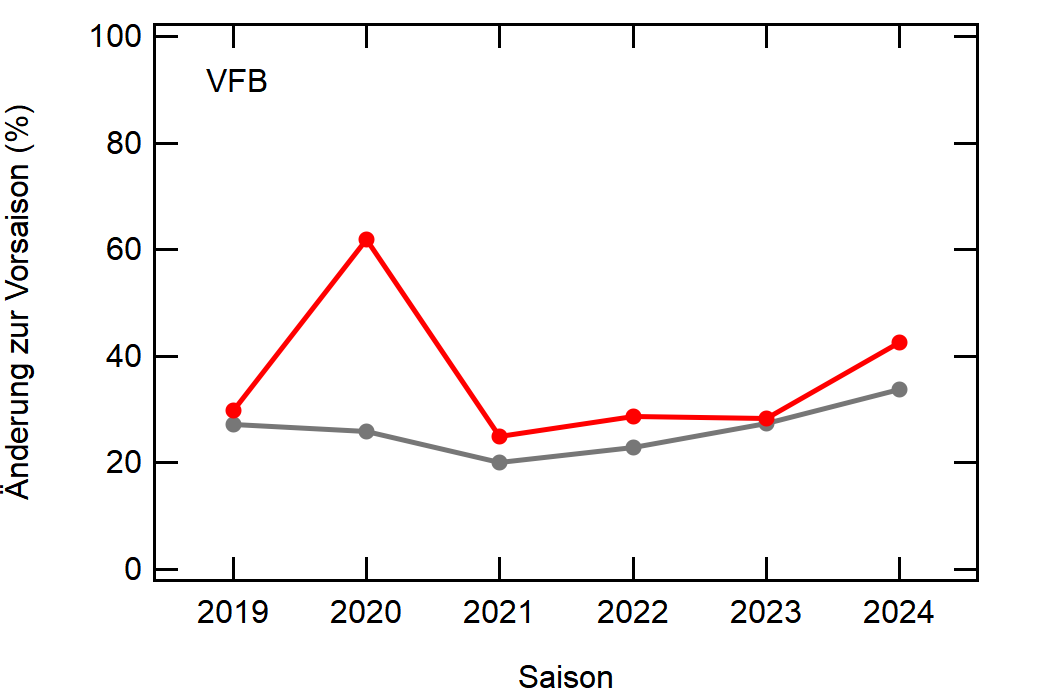
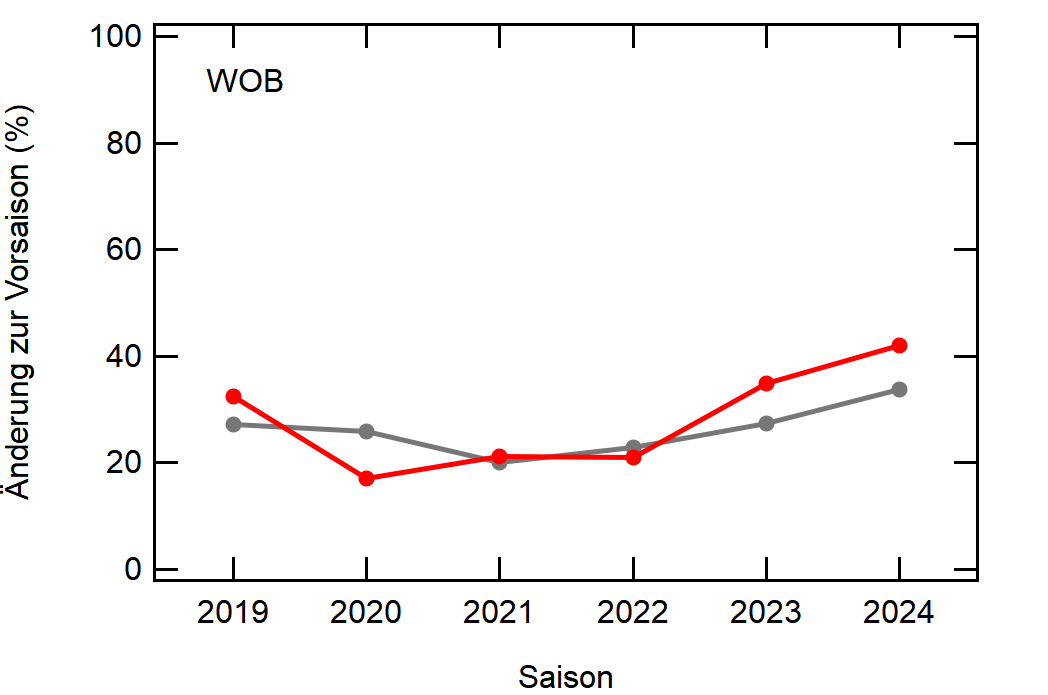
Hatte leider nicht die Zeit noch die Ligazugehörigkeit zu markieren, damit man Auf- und Abstiege besser erkennen kann. Falls ich dazu noch komme werde ich den Post hier aktualisieren, dann sind die Ausschläge besser zu beurteilen.
Kleine Beobachtungen:
- Bayern ist der einzige Verein, der konstant unterhalb des Mittelwertes ist und seinen Kader nur wenig verändert
- Hertha hat seinen Kader mit jeder Saison noch mehr verändert. Die ansteigende Kurve heißt nicht, dass der Kader gleichmäßig verändert wurde, sondern die Änderungen mit jeder Saison noch krasser wurden
- Arminia Bielefeld

- Leipzig war vor 5-6 Jahren noch sehr konservativ bei den Transfers, aber inzwischen werden sie auch langsam zum Durchlauferhitzer
- Wolfsburg bewegt sich überraschend dicht am Mittelwert entlang, dafür dass sie soviel Umsatz haben bei den Transfers. Heißt das, die neuen Spieler zünden nicht und am Ende spielen doch nur wieder die alten?
[1]: Namentlich sind das BMG, BVB, FCA, FCB, LEV, M05, RBL, SCF, SGE, TSG, WOB
EDIT: Hatte in einer ersten Version einmal zuviel quadriert. Habe es korrigiert und Graphen entsprechend angepasst.
3 „Gefällt mir“
Die Sportschau untersucht im Rahmen eines Vorberichtes zu Bayern – Wolfsburg (f) ob der FCB inzwischen WOB den Rang abgelaufen hat. Dazu werden einige statistische Auswertungen vorgenommen, u.a. „Expected Points“ und den GSN-Index, einen Index von GSN (Global Soccer Network) .
Mehr zum Hintergrund: Das steckt hinter dem NDR Fußball-Datenprojekt | NDR.de - Sport - Fußball
1 „Gefällt mir“
Auswirkung von unterschiedlichen xG Modellen auf die xPts
Einige kennen das wahrscheinlich nach einem Spiel sieht man von verschiedene xG-Werte von verschiedenen Anbietern. Je nach Spiel fällt die Variation der Werte mal größer oder kleiner aus. Mittlerweile gibt es auch schon so viele Anbieter, dass man auch die Auswahl hat sich zwischen den verschiedenen Anbietern zu entscheiden. Bei dem Wert expected Points (xPts) hingegen ist mir mit understat nur der eine Anbieter bekannt, daher kam in mir die Idee auf, wie sehen die xPts aus, wenn diese auf den Werten von einem xG-Modell basieren. Also habe ich mich mal dran gemacht selbst aus den Daten von fbref/Opta die xPts für die laufende BL-Saison der Männer & meine Ergebnisse auch mit den Werten von understat zu vergleichen.
Methodik
Wichtig ist es für die Berechnung, dass einem für alle Schüsse die xG-Werte vorliegen. Wenn stattdessen für die Spiele die xG-Werte fürs ganze Spiel genommen und durch die Anzahl an Schüssen geteilt werden bekommt man verzerrte Siegwahrscheinlichkeiten. Das bedeutet schlussendlich sind die xPts auch verzerrt. Wenn ich die genaue Stochastik dahinter klären würde, könnte das zu viel werden. Für die Stochastik-Interessierten möchte zumindest erwähnen, dass für die Berechnung die verallgemeinerte Binomialverteilung zu Grunde liegt. Die Grundannahme bei dieser Verteilung ist, dass die Zufallsvariablen unabhängig von einander sind. Um das jetzt wieder in den Fußball oder auch xG Kontext zu bringen, alle Schusssituationen werden als unabhängig angesehen. Gerade bei Doppel- und Mehrfachchancen würde wohl niemand so eine Aussage treffen. Ein Beispiel dafür:
Ein Spieler tritt beim Elfmeter an(0.75xG). Der Torwart kann den Ball halten, jedoch bekommt der Schütze einen qualitativ hochwertigen Nachschuss (0.4xG). Wenn wir die beiden Schüsse als unabhängig voneinander annehmen würden, wäre unsere Erwartungen an den Schützen, dass dieser aus den zwei Schüssen im Durchschnitt 1.15 Tore erzielt. Das macht in dem Fall keinen Sinn, daher nimmt man in dem Fall die zwei Schüsse raus & berechnet stattdessen einen xG-Wert für die Gesamtsituation.
Die Schwierigkeit ist, dass im Datensatz nicht direkt mitgeliefert wird, ob ein Schuss zu einer Doppel- oder Mehrfachchance gehört. Über die Shot Creating Actions(SCA) hat man aber dann doch zumindest teilweise die Chance solche Mehrfachchancen zu identifizieren. SCA1 ist dabei die letzte Aktion davor und SCA2 ist die vorletzte Aktion davor. Für mich war dann das Kriterium einer Mehrfachchance erfüllt, wenn SCA1 ein Schuss war oder wenn SCA2 ein Schuss war und SCA1 kein Foul oder kein Standard war. Alle Mehrfachchancen konnte ich so zwar nicht erfassen aber sehr viele. Ein Beispiel wo ich es nur teilweise hinbekommen konnte gibt es im Spiel Leverkusen gegen Heidenheim in der 45.Minute.

Boniface Abschluss bei 3:34, Frimpongs Kopfball bei 3:40 und nochmal Boniface bei 3:41 konnte ich anhand der Daten als eine Chance erfassen. Jedoch konnte ich den Hofmann-Abschluss 3:48 nicht mehr als Teil der Chance erfasst, obwohl ich beim Ansehen sagen würde, alle vier Schüsse sind Teil derselben Mehrfachchance.
So viel zur Methodik, davor aber noch ein kleiner Einschub: Direkt vor der Mehrfachchance im Video hat Kleindienst einen Abschluss. Dieser Schuss hat einen Post-Shot xG(PSxG) Wert von 0.92 bekommen, da muss Opta noch am eigenen Modell arbeiten. So wie der Ball Hradecky in die Arme hoppelt, hätte das Tor auch ein Feldspieler mit dem Fuß verhindern können. Mein Tipp ist, die Schussgeschwindigkeit ist keine Variable im Opta-Modell. Soll nur als kurze Einordnung vom PSxG-Wert auf fbref dienen.
Endresult Tabelle mit xPts
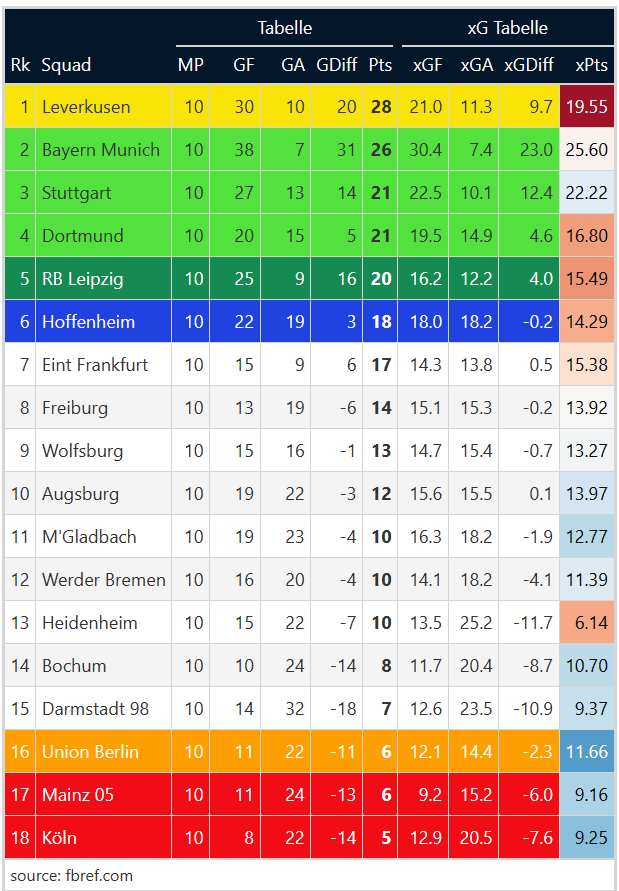
Erstmal zur Farbgebung von den Zellen der xPts. Rot bedeutet, ein Verein hat mehr Punkte gesammelt als der xPts-Wert erwarten lässt. Blau hingegen bedeutet das genaue Gegenteil. Je dunkler die Farbe, um so mehr wurde der xPts über- oder auch untertroffen.
Im Großen und Ganzen weichen die xPts-Werte der meisten Vereine nur um maximal 0.5 von den Werten bei understat ab. Den deutlichsten Unterschied gibt es bei Hoffenheim, die bei mir 1.65 xPts mehr bekommen. Die drei weiteren Vereine, die noch am deutlichsten abweichen, sind der 1.FC Köln (-1.1 xPts), RaBa Leipzig (-1.07) und Leverkusen (-0.78).
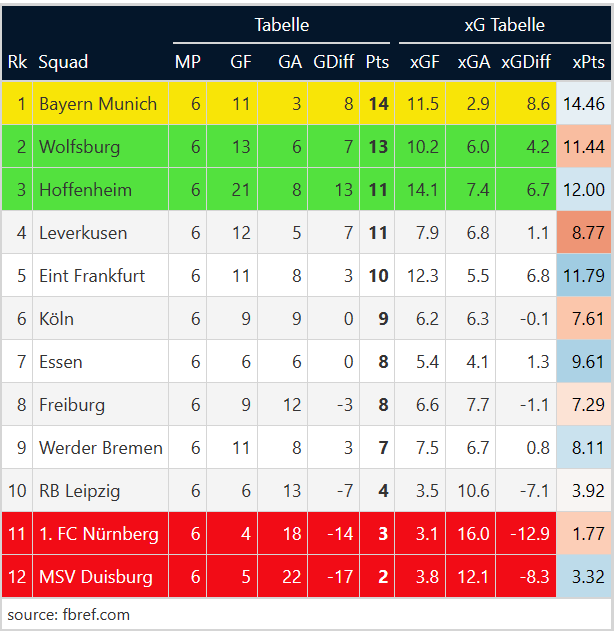
Da der Code nur minimal am Anfang abgeändert werden musste habe ich das auch noch für die Frauen-Bundesliga erstellt. Ist jetzt zwar noch nicht so ganz relevant für mich (erst in zwei Jahren, wenn die 05erinnen auch erstklassig sind
4 „Gefällt mir“
wirklich schöne Auswertung, vielen Dank. Die xPnts berechnen sich eindach aus der xG Differenz im Spiel und wenn die kleiner 1 ist, wird es als unentschieden bewertet? oder gibt es da kompliziertere Formeln wie beim ELO?
Bin nur gerade fasziniert, dass Dortmund fast genau auf den xG und xGA werten liegt, aber bei den xPnts um 25% danaben liegt.
Es wird nachträglich berechnet wie wahrscheinlich es war, dass Team 1 oder Team 2 das Spiel gewinnt oder das Spiel unentschieden ausgeht. Die Siegwahrscheinlichkeiten werden berechnet in dem man die Wahrscheinlichkeiten für die Anzahl der Tore berechnet. Ich zeige es mal an einem winzigen Beispiel:
Team 1 hatte 2 Schüsse (0.45, 0.02) und Team 2 hatte im Spiel 4 Schüsse (0.3, 0.1, 0.25, 0.05). Ich wähle bewusst so wenige Schüsse, da ansonsten die Dimensionen viel zu groß werden, um es hier zu zeigen. Als erstes berechne ich wie wahrscheinlich es war, dass Team 1 0, 1 oder 2 Tore schießt.
P(X = 0 Tore) = (1 - 0.45) * (1 - 0.02) = 0.539,
P(X = 1 Tor) = (0.45 * 0.98) + (0.55 * 0.02) = 0.452, P(X = 2) = 0.009
Dann macht man das auch für Team 2.
P(Y = 0 Tore) = 0.4489, P(Y = 1) = 0.4155, P(Y = 2) = 0.1228, P(Y = 3) = 0.0125, P(Y = 4) = 0.0004
Siegwahrscheinlichkeit für Team 1 berechnet man, dann wie folgt
P(X > Y) = P(X > 0 | Y = 0) + P(X > 1 | Y = 1) = P(X = 1, 2 | Y = 0) + P(X = 2 | Y = 1) = P(Y = 0) * (P(X = 1) + P(X = 2)) + P(Y = 1) * P(X = 2) = 0.211
P(X = Y) = 0.431 Wahrscheinlichkeit für ein Unentschieden
P(Y > X) = 0.358 Siegwahrscheinlichkeit für Team 2
Wenn man dann die dazugehörigen Punkte mit den Wahrscheinlichkeiten multpliziert und das dann zusammen addiert bekommt man schlussendlich die xPts raus. Team 1 werden dann 3 * 0.211 + 1 * 0.431 = 1.064 xPts für das Spiel zugeschrieben und für Team 2 1.505 xPts.
Ich habe das zwar vorher bewusst vermieden, aber ich hoffe so wurde es klarer.
Der Dortmund Fall ist schon ein bisschen kurios. Wobei die xG bestätigen eigentlich nur den Eindruck, den schon die Tordifferenz vermittelt, Dortmund ist nicht wirklich dominant gewinnt aber viele enge Spiele. Wenn ein Team 5 Siege mehr als Niederlagen hat erwartet man normalerweise eine Tordifferenz > 5. Dortmund war in den Spielen bisher häufig nur leicht und nicht klar besser, dann ist das Risiko natürlich auch höher Punkte abzugeben. Dementsprechend ist trotz quasi gleichen Werten bei Toren und xG, der xPts Wert um 4.2 niedriger als die tatsächlichen Punkte.
2 „Gefällt mir“
Super spannend, vielen Dank dir! Es gibt grundsätzlich so viele Situationen, in denen sich die Tabelle nicht wirklich aussagekräftig anfühlt (Am Anfang einer Saison, aber v.a. generell, wenn man Mannschaften im Hinblick auf ihre aktuelle Formstärke betrachtet), und die xPts sind da meiner Wahrnehmung nach noch einmal eine ganze Ecke hilfreicher als die xG. Ist vielleicht auch ein Tool, mit dem man Mannschaften einschätzen kann, die man nur wenig gesehen hat (z.B. wie gut ist Girona tatsächlich? oder so). Kannst du dir vorstellen, den Code frei verfügbar zu machen? Versteh natürlich auch, wenn du da Vorbehalte hast.
Ganz andere Thematik, wurde vielleicht auch an anderer Stelle schon einmal besprochen, als es um advanced stats ging: Kann mir jemand den rise and fall der packing rate erklären? Ich fand es damals, als die packing rate im TV auf einmal so gehyped wurde, oftmals erleuchtend. Für die breite Masse war das damals scheinbar nicht interessant, aber irgendwann habe ich dann letztlich auch von nischigeren Fußball-Kanälen mit Datenbezug quasi gar nichts mehr von der packing rate gehört.
Klar kein Problem, auch für den Fall, dass es andere nutzen wollen. Man kann damit für alle Ligen, die es bei Fbref mit xG gibt, solche Tabellen erstellen. Es ist auch möglich Saisons zurückzugehen, wobei die Saisons erst ab einem gewissen Zeitpunkt mit xG geführt werden.
Der Code ist mit R geschrieben. Ich habe es einigermaßen einsteigerfreundlich gemacht, weshalb ich es auf 3 Skripte aufgeteilt habe, die vom Namen her selbst erklärend sein sollten. Die Codeabschnitte, an denen man Anpassungen vornehmen kann, stehen direkt nach dem Einlesen der Packages. Zum einen ist es eine Variable, die den Dateinamen zum Abspeichern festlegt, und zum anderen die Funktion fb_match_results aus dem Package worldfootballR. Die Funktion lädt die Daten von fbref runter. Die Dokumentation sollte man sich anschauen, um zu wissen wie man Land, Jahr, Geschlecht oder Ligaebene ändert. Wenn man das gemacht hat kann man den Code durchlaufen lassen. Ich habe ihn aber auch kommentiert, so dass einigermaßen klar sein sollte, was gemacht wird.
Tabelle_xPts.zip (4,5 KB)
Ich kann zu dem Packing Thema nichts wirklich sagen, aber das Unternehmen gibt es noch. Oft ist es auch eine Strategiefrage, wie diese Unternehmen auftreten wollen. Die EM 2016 wurde sicher genutzt, um sich als neues Unternehmen auf dem Markt zu platzieren. Es würde mich nicht überraschen, wenn die ARD damals nichts dafür zahlen musste.
2 „Gefällt mir“
Sehr schön. Wollte direkt prüfen, ob deine verbesserten xPts besser mit dem Power Index Modell von 538 korrelieren als normale xPts, nur um festzustellen, dass sie ihren Sportbereich nach der ABC/Disney Übernahme im Sommer komplett eingestellt haben ![]()
War immer mein liebster Anlaufpunkt um auf die schnelle nach Über/unterperformance zu gucken.
Ich werde deine Dokumentation aber gerne als Anreiz nehmen, mich Mal wieder mit R zu beschäftigen ![]()
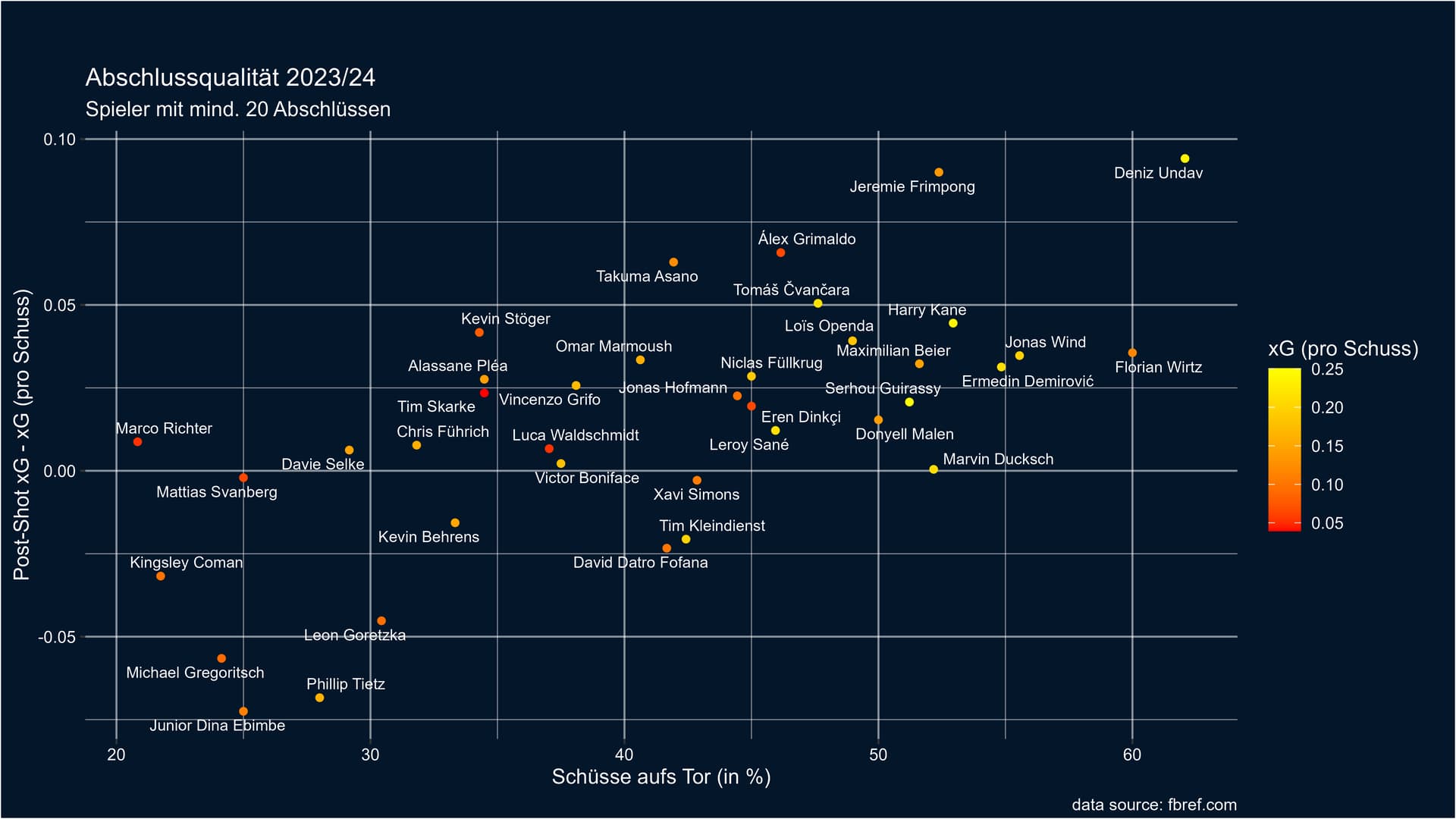
Abschlussqualität einzelner Spieler in der bisherigen BL-Saison
Ich bin wieder ein bisschen in die Welt der Daten und Statistiken abgetaucht. Dieses Mal hat es mich beschäftigt, wer eigentlich diese Saison von allen Spielern, die beste Abschlussqualität aufweist. Dafür habe ich mich zum einen aus offensichtlichen Gründen der Torschussquote bedient und zum anderen der Differenz aus Post-Shot xG und xG, die zeigen soll ob ein Spieler durch seinen Abschluss die Wahrscheinlichkeit auf ein Tor im Durchschnitt vergrößert oder verschlechtert. Dafür möchte ich kurz auf den Post-Shot xG Wert eingehen.
Ich hatte schon bei xPts Tabelle etwas zum Post-Shot xG Wert von fbref/Opta gesagt gehabt, da mir zufällig etwas aufgefallen war.
Das möchte ich zum einen Vorweg schicken, dass das Modell für die Post-Shot xG sicher nicht das beste Markt sein wird. Ein weiterer Aspekt ist, dass ich nicht genau weiß ob das Modell auf Torhüter oder Feldspieler angelegt ist. Wenn es auf Torhüter ausgelegt ist, ist es nämlich sinnvoll deren Positionierung für die Post-Shot xG nicht ins Modell aufzunehmen, um Torhüter mit besserem Positionsspiel nicht genau dafür zu bestrafen. Wenn man jedoch die Abschlussqualität von Spielern bewerten will sollte die Positionierung des Torwarts im Modell sein, da es je nach Positionierung schwieriger oder einfacher ist, ein Tor zu erzielen. Meine Vermutung ist, dass es auf die Torhüter angelegt ist, da diese Statstik nur bei diesen aufgeführt wird. Außerdem ist anzumerken, dass nur Schüsse, die gehalten wurden oder reingegangen sind, einen Wert größer als 0 aufweisen. Es ist dementsprechend egal, ob ein Ball auf der Torlinie oder im Getümmel an der Strafraumkante geblockt wird. Man kann es natürlich kritisch sehen, dass ein auf der Torlinie geklärter Schuss den Wert 0 bekommt, in dem Fall muss man es einfach akzeptieren.
Also wenn es doch zu deutlicheren Abweichungen zu der eigenen Wahrnehmungen kommen könnte kann das mit den erklärten Faktoren zusammenhängen.
Nun also zu den Grafiken, die Punkte sind farbig unterlegt, so dass man auch eine grobe Idee hat wie gut durchschnittlich die Position ist, aus der die Spieler den Abschluss suchen. Das erklärt dann nämlich auch warum Marco Richter einen positiven Wert hat, obwohl er nur knapp über 20% seiner Schüsse aufs Tor bringt.
Bei der zweiten Grafik habe ich Elfmeter rausgelassen, da Elfmeter und Schüsse aus dem Spiel heraus als unterschiedliche Art an Abschlüssen angesehen werden können. Selbiges könnte man natürlich auch mit Freistößen machen, habe ich jetzt aber noch nicht gemacht.
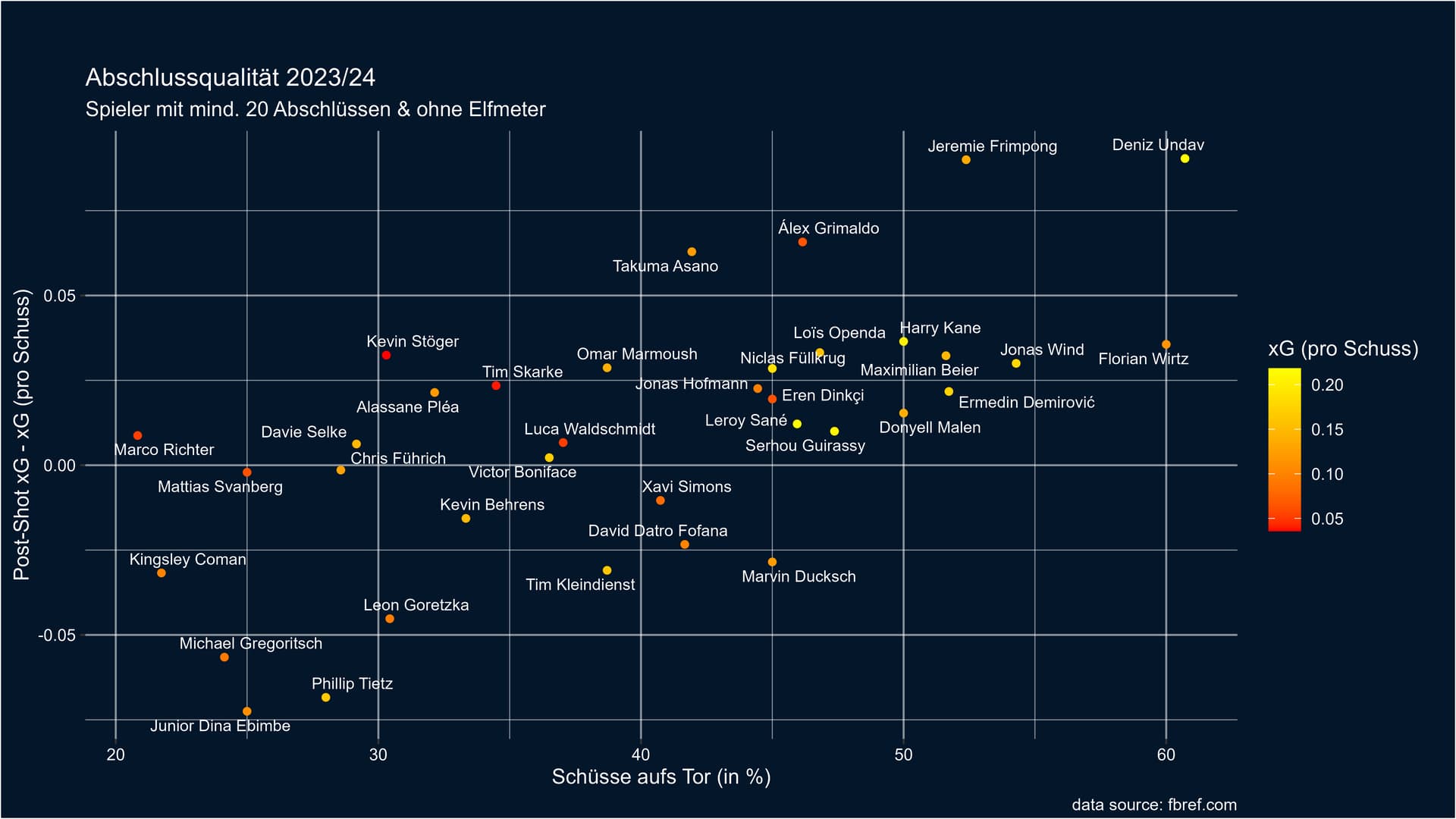
Überraschend ist wie Guirassy abschneidet, der zwar auch einen positiven Wert erreicht, sich aber nicht wie man es erwarten würde von der Masse absetzen kann. Hingegen überragt sein Stuttgarter Sturmkollege Undav alle anderen BL-Spieler. Ebenso bemerkenswert ist auch Frimpong. Bei seinem Teamkollegen Grimaldo habe ich diese Positionierung fast schon erwartet, wenn daran denkt aus welchen Positionen er schon getroffen hat. Im negativen Sinne fällt dann jemand wie Gregoritsch auf, der bisher nur ein Saisontor erzielt hat.
Mich hat dann noch interessiert wie Robert Lewandowski in den letzten Saison abgeschnitten hat, da man ihn sicher als den Goldstandard in der BL in den letzten 10 Jahren bezeichnen kann. Die weißen Punkte sind die Punkte der Spieler aus der Grafik darüber.
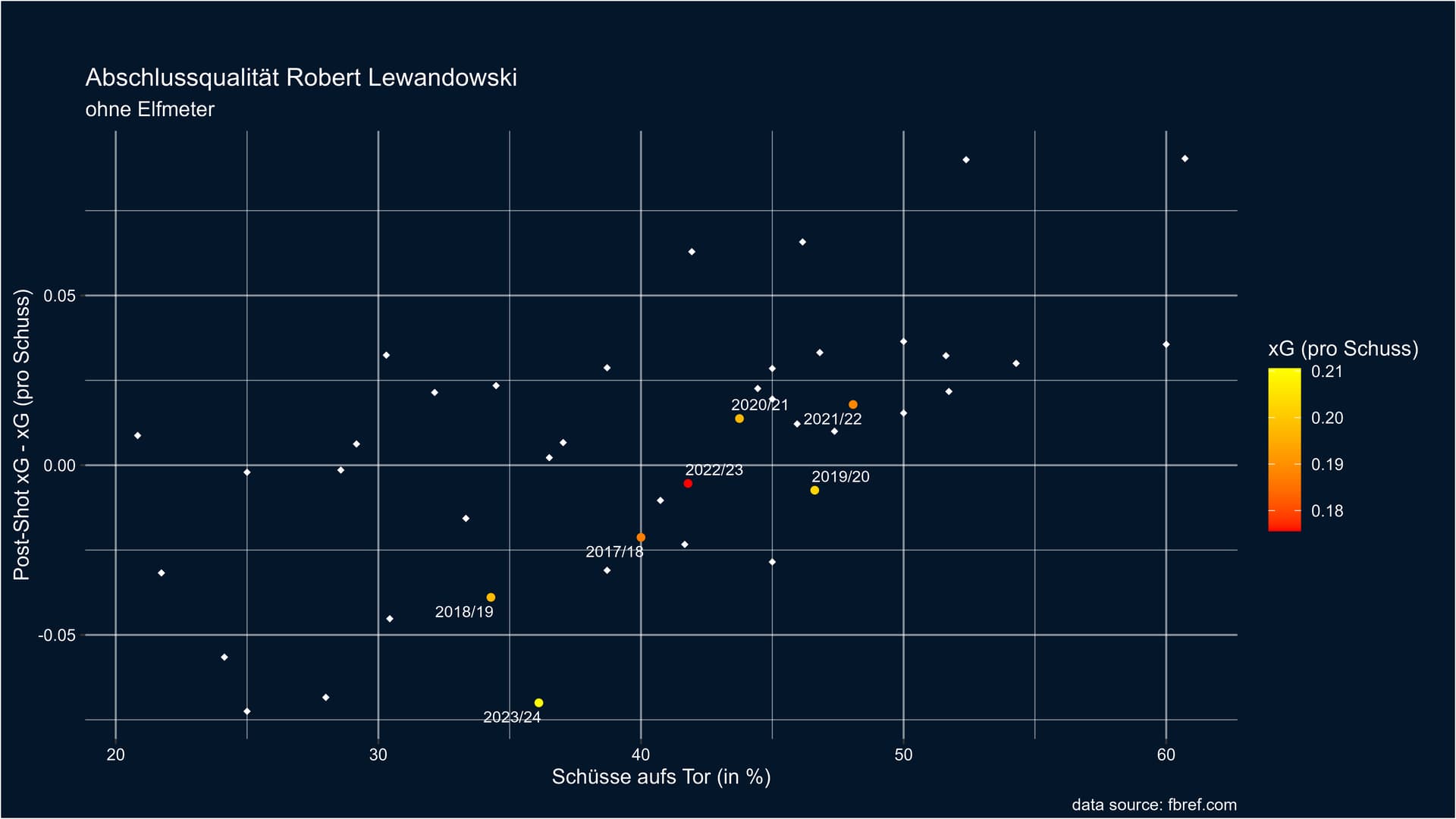
Für mich war es doch etwas überraschend zu sehen, dass er abgesehen von seiner Rekordsaison und letzten Saison bei den Bayern keinen positiven Wert bei der Differenz zwischen Post-Shot xG und xG aufweisen kann. So ganz erklären kann ich mir das tatsächlich nicht. Ein bisschen beruhigt mich hingegen die Tatsache, dass mit 2018/19 und 2023/24 die beiden Saison negativ herausstechen, in denen er recht deutlich seinen xG-Wert unterperformt hat bzw. aktuell unterperformt.
Also von einem gewissen Erklärwert kann man schon ausgehen, jedoch würde ich auch nicht aufgrund der angesprochenen möglichen Probleme von einer fehlerfreien Darstellung der Abschlussqualitäten ausgehen.
3 „Gefällt mir“
Nice! Solche Zahlen schaue ich mir ja gerne an.
Wenn man mal annimmt, dass Lewandowski nicht wirklich jede Saison plötzlich gut oder schlecht schießen kann, dann ist die Verteilung von ihm eine Visualisierung der recht großen Messunsicherheit. Aber selbst wenn man die an Undav gedanklich anlegt, bleibt er ein Phänomen.
Würde vielleicht noch empfehlen, die x Achse als Anteil Schüsse aufs Tor oder so umzubenennen, damit es noch einmal ein Tick mehr selbsterklärender ist. Aber ich liebe die Grafiken!!!
Das ist mehr ein Meta-Beitrag:
Bin vor Kurzem über einen Artikel im RBB gestoßen, der nochmal schön und verständlich einige statistische Werte erklärt und die Kritik an diesen gleich mitliefert: Zweikampf mit dem Zahlensalat
Dürfte für die meisten hier keine vollkommen neue Information sein, aber ich finde der Artikel gibt die wichtigsten Punkte pointiert mit, sodass man ihn hervorragend als Erklärungshilfe für interessierte ‚Unbeleckte‘ benutzen kann.
PS: Ich wollte den auch einfach teilen und dafür keinen neuen Beitrag aufmachen.
4 „Gefällt mir“