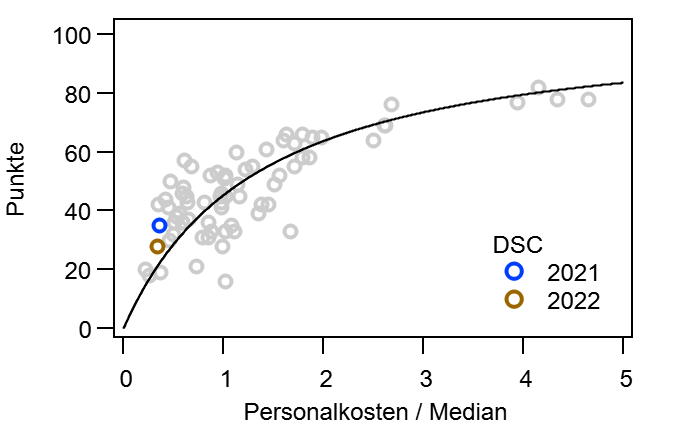
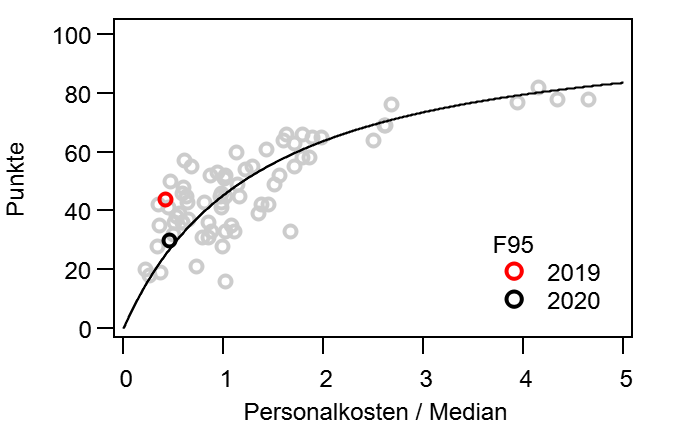
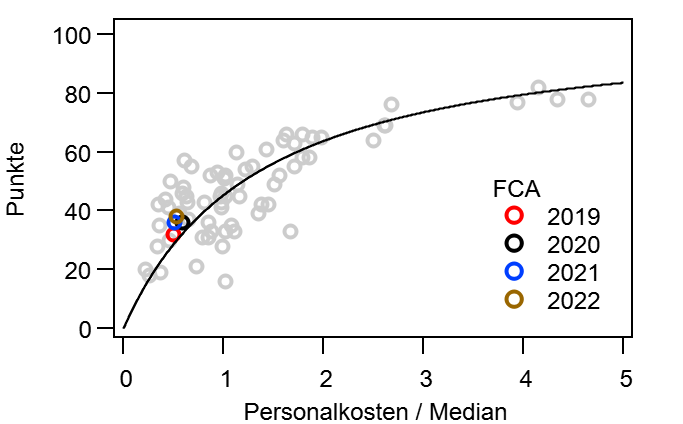
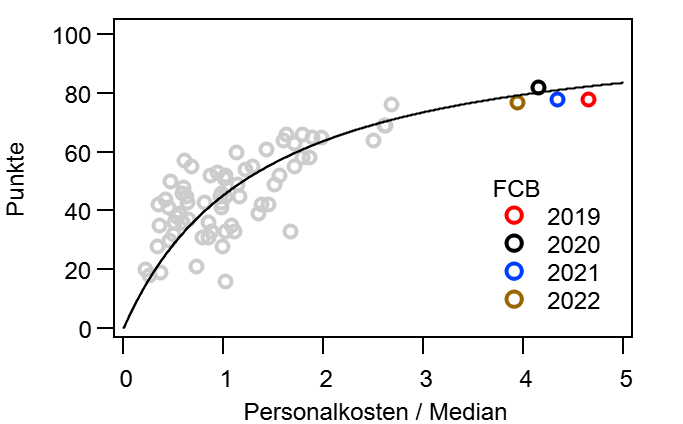
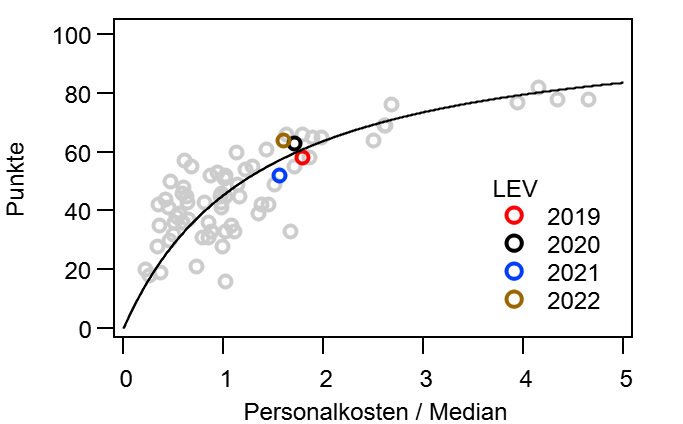
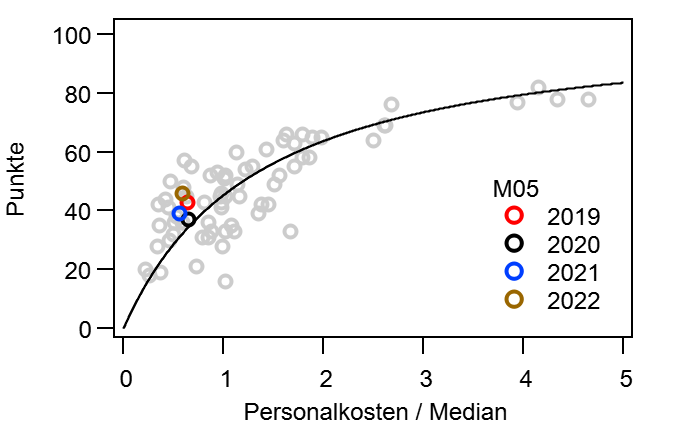
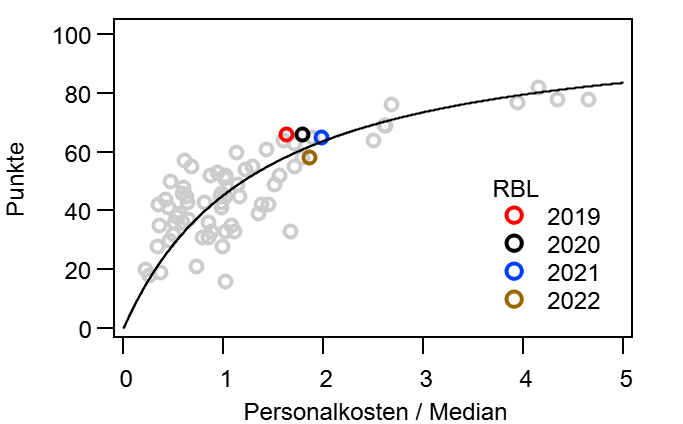
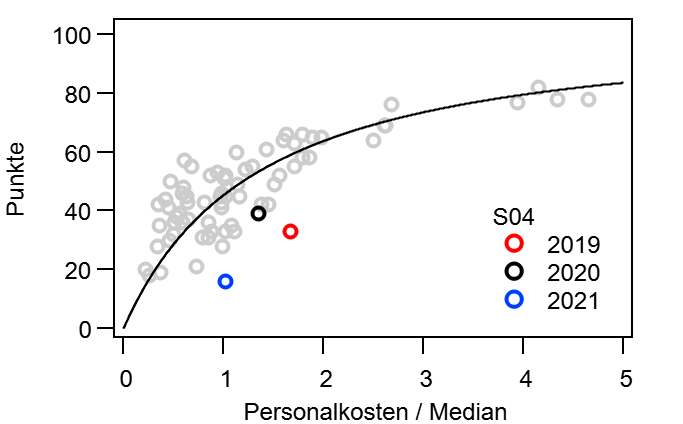
Dann mache ich mal den Anfang. @bizzmane hatte vor einiger Zeit vorgeschlagen mal zu schauen, wie sich die Tabelle im Laufe einer Saison entwickelt, vor allem im Vergleich mit der Endtabelle. Während dieser „kurzen Auswertung“, tat sich aber ein kleiner Kaninchenbau auf und ich Trottel habe natürlich die rote Pille gewählt… Ich bitte hier schon einmal um Entschuldigung, dass es so lang geworden ist.
Kurze Warnung: Am Anfang wird es etwas trocken und technisch, dann wird es nerdy aber am Ende dann hoffentlich auch interessant. Außerdem noch der übliche Disclaimer: Das hier ist das Rasenfunkforum und kein Peer Review Journal, von daher das Folgende bitte nicht als die reine und unumstößliche Wahrheit sehen.
Wie wird gemessen?
Wenn wir zwei Tabellen miteinander vergleichen, gibt es intuitiv zwei Möglichkeiten dies zu tun:
-
Vergleiche für jedes Team die Positionen in beiden Tabellen und addiere die Differenz über alle Teams auf. Hier geht es also nur um die Position der Teams in den Tabellen, daher werde ich im Folgenden den Ausdruck „Position“ verwenden, wenn ich diese Zählweise meine.
-
Vergleiche für jede mögliche Paarung zweier Teams, ob Team A besser oder schlechter ist als Team B. Wenn dieser Vergleich in den beiden Tabellen unterschiedliche Ergebnisse gibt, gibt es einen Strafpunkt und am Ende werden alle Punkte aufsummiert. Hier geht es also nur um den relativen Vergleich zwischen den Teams, daher werde ich im Folgenden den Ausdruck „Relativ“ verwenden, wenn ich diese Zählweise meine.
Da ich nicht sagen kann welche Zählweise die Bessere ist, verwende ich einfach beide. Das hat auch den Vorteil um sicherzustellen, dass die Ergebnisse nicht durch die Zählweise beeinträchtigt werden. Für eine bessere Vergleichbarkeit, müssen die beiden Zählweisen renormiert werden: Dafür habe ich eine Tabelle genommen und eine Millionen mal die Reihenfolge zufällig auswürfeln lassen. Die randomisierten Tabellen wurden dann mittels beiden Zählweisen mit der Ausgangstabelle verglichen und resultierten beide Male in einer schönen gaußschen Glockenkurve – jeweils zentriert um 108 Punkte (Position) und 76,5 Punkte (Relativ). Daher werden diese beiden Werte jeweils als „100% Unordnung“ definiert. Werte kleiner als 100% heißen dementsprechend, dass es bereits eine gewisse Ordnung gibt und bei 0% sind die Tabellen identisch. Theoretisch wären im Einzelfall auch Werte von über 100% möglich, das wäre aber ein Indiz für Ordnung in entgegengesetzter Richtung und daher unwahrscheinlich. Bei ausreichend großen Stichproben sollte dies aber nicht auftreten – und wird hier auch nicht auftreten.
tl;dr: Zwei unterschiedliche Zählweisen, wobei beide so skaliert werden, dass ein Wert von 100 „absolutes Chaos“ bedeutet während ein „perfect match“ in einem Wert von 0 resultiert.
Saisons der letzten 30 Jahre:
Für die Auswertung, habe ich mir die Saisonverläufe 1992/93 bis 2021/22 angeschaut und durchgehend die Drei-Punkte-Regel angewandt. Nach jedem Spieltag wurde die Spieltagstabelle mit der Endtabelle verglichen und die Unordnung notiert.
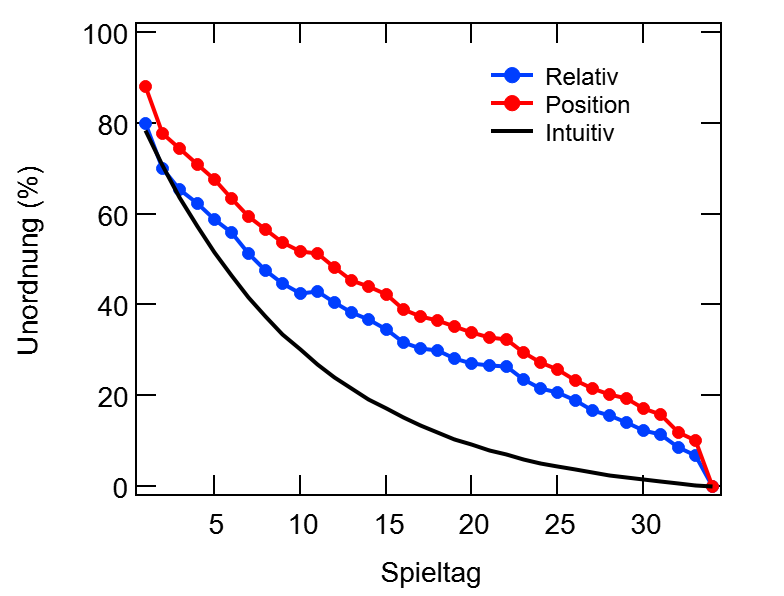
Der gemittelte Verlauf aller 30 Spielzeiten ist in Abbildung 1 für beide Zählweisen dargestellt und in beiden Fällen ist er in etwa linear. Dies hat mich überrascht, da ich intuitiv einen Verlauf erwartet hatte, der zumindest etwas asymptotisch ist (vgl schwarze Linie).
Abbildung 1
Hier tat sich dann auch der Kaninchenbau auf. Was macht man nämlich, wenn man einen komplexen Sachverhalt nicht versteht? Man baut sich ein eigenes Modell und spielt damit rum!
Ich bau’ mir ein Schloss aus Sand Modell
Um die Saisonverläufe zu simulieren, habe ich die gleichen Spielpläne verwendet und vorher für die 18 generischen Teams ein Power Ranking erstellt. Wenn nun zwei Teams gegeneinander spielen, ist der Ausgang abhängig von der Differenz ihrer Positionen im Power Ranking. Dafür habe ich mich an dem ELO Modell im Schach bedient und etwas abgewandelt, aber ich will euch an dieser Stelle nicht mit den Details langweilen. Wichtig ist nur: Es gibt einen Parameter Z mit dem man den Einfluss des Zufalls dosieren kann. Bei Z=0 gibt es keinen Zufall und das bessere Team gewinnt immer. Dieser Fall ist dargestellt in Abbildung 2 als hellste graue Linie. Wenn immer das bessere Team gewinnt, gibt es einen etwas asymptotischen Verlauf bis zum 17ten Spieltag, da hier jedes Team einmal gegen jedes andere gespielt hat. Mit Beginn der Rückrunde bricht diese Ordnung wieder auf, da der Spielplan wieder etwas Unordnung rein bringt, bis es zum Ende der Saison wieder perfekt sortiert ist.
Abbildung 2
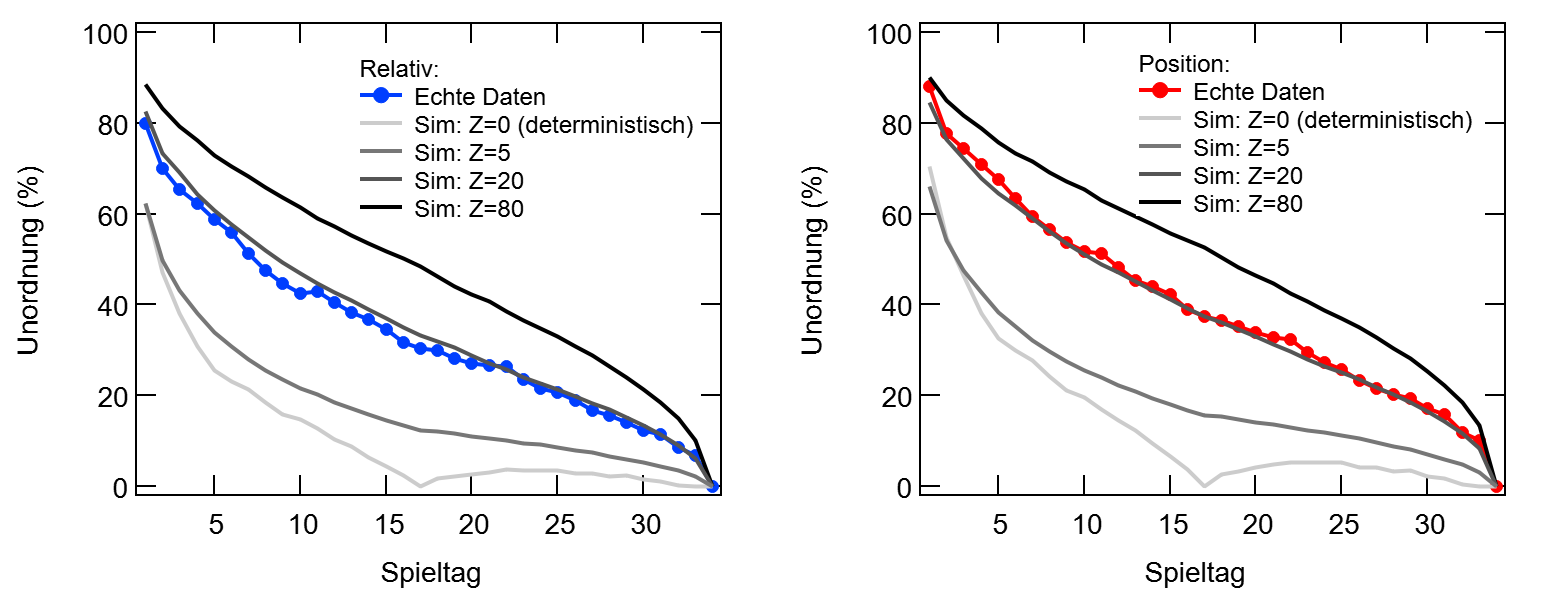
Die dunkelgrauen Linien in Abbildung 2 entsprechen Saisonverläufe für verschiedene Werte für Z. Wie man erkennen kann, wird der Saisonverlauf relativ gut reproduziert für einen Wert von Z=20. Dies entspricht einer Sieg-Unentschieden-Niederlage Wahrscheinlichkeit von 35% : 33% : 32% bei einem Platz unterschied im Power Ranking und 51% : 31% : 18% bei 10 Plätzen Differenz.
Wenn man sich jetzt aber mal die Endtabelle anschaut, stellt man fest: Die entspricht ja gar nicht dem Power Ranking! Bei Z=20 ist der Zufall so groß, dass er sich über eine Saison nicht wegmitteln kann. In Abbildung 3 sind nun drei Saisonverläufe dargestellt: Die echten Daten (Kreise) und zwei simulierte Saisonverläufe mit Z=20, einmal mit der Endtabelle as Referenz (schwarz) und einmal mit dem tatsächlichen Power Ranking (orange). Wenn ich die Endtabelle als Referenz nehme, wird der Saison natürlich bei 0% enden, da die Tabelle am letzten Spieltag mit sich selbst verglichen wird. Beim Vergleich mit dem tatsächlichen Power Ranking ergibt sich dagegen der eingangs erwartete asymptotische Verlauf, der nach 34 Spieltagen jedoch bei Weitem noch nicht nahe der 0% ist. Wenn man diesem simplen Modell halbwegs Glauben schenken möchte, besteht die Tabelle nach einer Saison je nach Zählweise noch zu etwa 40% aus Unordnung! Oder anders Ausgedrückt: Eigentlich ist die Bundesliga Saison (nach diesem Modell) viel zu kurz.
Abbildung 3
(An dieser Stelle noch der Hinweis: Ich möchte nicht den Bayern ihre Meisterschaft absprechen. Die haben diese absolut verdient gewonnen (was ja irgendwie das Problem der BuLi ist). Es geht hier um Teams die nahe beieinander liegen, also zum Beispiel beim Kampf um die internationalen Plätze, wo wenige Punkte und Tore den Unterschied machen.)
Sagen sie „Stopp“
Wie lang müsste die Saison denn dann eigentlich sein? In Abbildung 4 ist der mittlere Saisonverlauf dargestellt (Power Ranking als Referenz), wenn eine Saison 10 Jahre gehen würde. Dafür habe ich nicht die gleiche Saison 10 mal spielen lassen sondern verschiedene Spielpläne gemischt um irgendwelche Artefakte zu vermeiden. Wie oben erwähnt, ist nach einem Jahr noch etwa ein 40% Unordnung in der Tabelle, während es nach 3 Jahren noch ein Viertel sind. Um den Wert auf 10% zu drücken muss man schon mehr als 10 Jahre spielen lassen. Um das ganze etwas Anschaulich zu gestalten: Nach 2 Jahren sind die Teams im Mittel noch knappe zwei Plätze von ihrem tatsächlichen Power Ranking entfernt und nach 8 Jahren noch ein Platz im Mittel.
Abbildung 4
Hier muss aber ein sehr großes Sternchen gemacht werden, da wir schon jenseits der Grenzen dieses einfachen Modells sind. Um den tatsächlichen mittleren Verlauf zu reproduzieren haben wir ein fixes/statisches Power Ranking definiert und dann ausreichend „Zufall“ hinzugefügt, der alle möglichen Faktoren erschlägt. In der echten Welt gibt es neben dem Zufall viele weitere Faktoren wie Verletzungen, Transfers, Trainerwechsel, Dreifachbelastung, Form und so weiter und so fort. Das heißt in der Realität ist das Power Ranking eben nicht statisch sondern verändert sich ständig. Dementsprechend würde eine Saison über 10 Jahre vermutlich gar nicht konvergieren, also sich nicht asymptotisch einen festen Wert nähern. Für eine einzelne Saison sollte das Modell aber eine halbwegs passable Näherung sein um das den Zufall – bzw das „Unerwartete“ – messbar zu machen.
Wenn man hier einen anschaulicheren Vergleich bemühen möchte: Eine Saison der Bundesliga ist wir ein unterbelichtetes Foto, bei dem die Anzahl der Spieltage der Belichtungszeit entspricht. In meinem simplen Modell war das Motiv aber ein einfaches Stillleben. Das heißt man könnte einfach die Belichtungszeit erhöhen und irgendwann wird man jedes Details genau erkennen können. In der echten Welt bewegt sich das Motiv aber. Eine längere Belichtungszeit wäre zwar heller, aber das eigentlich Motiv wäre verwaschen. Für kurze Belichtungszeiten sind die beiden Bilder aber vergleichbar.
Warum aber macht man es nicht einfach „heller“? Das liegt an der Natur des Fußballs. Der ist nämlich deswegen so „dunkel“, weil so wenig Tore fallen. Hätten wir Ergebnisse wie beim Basketball, gäbe es deutlich weniger „glückliche“ Siege, da man schwerer ein 1:0 nach Hause mauern kann. Auch Fehlentscheidung des Schiris wären dann nicht ganz so gewichtig. Dadurch hat dort meiner Meinung nach jedes einzelne Spiel mehr Aussagekraft als beim Fußball. Die entscheidende Frage wäre aber: Wollen wir das überhaupt?
Was haben wir heute gelernt?
Die Endtabelle der Bundesliga reflektiert nicht unbedingt wie gut ein Team die letzte Saison war, sondern (nur) wie gut es die letzte Saison gespielt hat (duh!). Dabei ist die Endtabelle zu etwa 40% aus „zufälligen“/unvorhersehbaren Faktoren bestimmt. Übrigens hatten @GNetzer und @Taktikfuchs bei ihren Tabellentipps letzte Saison das äquivalent von 42% Unordnung (Relativ Methode), sie waren also ziemlich dicht am vorhersagbaren Möglichen. Respekt!
Das Fazit ist also, wenn man den Vergleich von oben wieder bemühen möchte: Fußball ist wie eine Nacht in der Kneipe oder dem Club; es ist relativ dunkel und etwas chaotisch, aber wir haben unseren Spaß dabei – und ganz genau will man die Details ja gar nicht sehen, denn so bleibt noch Raum für Fantasie, Überraschungen und Hoffnung.